20 Vettori
20.1 Introduzione
Finora questo libro si è concentrato sulle tibble e sui pacchetti che lavorano con esse. Ma quando inizierete a scrivere le vostre funzioni e a scavare più a fondo in R, avrete bisogno di imparare i vettori, gli oggetti che sono alla base delle tibble. Se avete imparato R in modo più tradizionale, probabilmente avete già familiarità con i vettori, dato che la maggior parte delle risorse di R inizia con i vettori e si fa strada fino alle tibble. Penso che sia meglio iniziare con le tibble perché sono immediatamente utili, e poi lavorare fino ai componenti sottostanti.
I vettori sono particolarmente importanti perché la maggior parte delle funzioni che scriverete lavoreranno con i vettori. È possibile scrivere funzioni che lavorano con le tibbie (come ggplot2, dplyr e tidyr), ma gli strumenti necessari per scrivere tali funzioni sono attualmente idiosincratici e immaturi. Sto lavorando ad un approccio migliore, https://github.com/hadley/lazyeval, ma non sarà pronto in tempo per la pubblicazione del libro. Anche quando sarà completo, avrete ancora bisogno di capire i vettori, renderà solo più facile scrivere un livello user-friendly sopra.
20.2 Nozioni di base sui vettori
Ci sono due tipi di vettori:
- Vettori atomic, di cui esistono sei tipi: logical, integer, double, character, complex, e raw. I vettori interi e doppi sono conosciuti collettivamente come vettori numerici.
- Liste, che a volte sono chiamate vettori ricorsivi perché le liste possono contenere altre liste.
La differenza principale tra vettori atomici e liste è che i vettori atomici sono omogenei, mentre le liste possono essere eterogenee. C’è un altro oggetto correlato: NULL. NULL è spesso usato per rappresentare l’assenza di un vettore (al contrario di NA che è usato per rappresentare l’assenza di un valore in un vettore). NULL si comporta tipicamente come un vettore di lunghezza 0. La figura 20.1 riassume le interrelazioni.
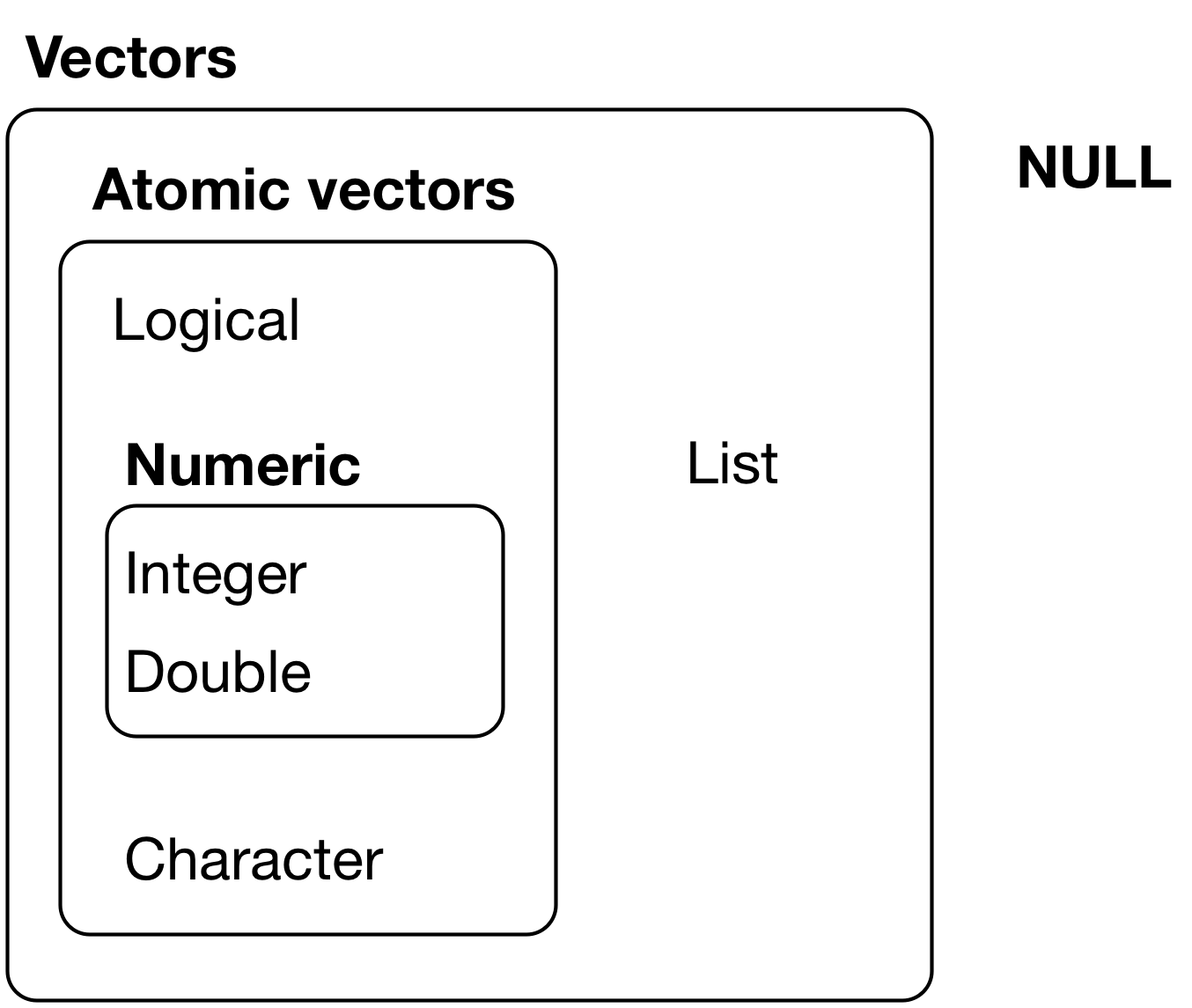
Figure 20.1: The hierarchy of R’s vector types
Ogni vettore ha due proprietà chiave:
-
Il suo tipo, che potete determinare con
typeof(). -
La sua length, che potete determinare con
length().
I vettori possono anche contenere metadati aggiuntivi arbitrari sotto forma di attributi. Questi attributi sono usati per creare vettori aumentati che si basano su comportamenti aggiuntivi. Ci sono tre tipi importanti di vettori aumentati:
- I fattori sono costruiti sopra i vettori interi.
- Date e date-ora sono costruiti sopra vettori numerici.
- I data frame e le tibble sono costruiti sopra le liste.
Questo capitolo vi introdurrà a questi importanti vettori dal più semplice al più complicato. Inizierete con i vettori atomici, poi arriverete alle liste, e finirete con i vettori aumentati.
20.3 Tipi importanti di vettori atomici
I quattro tipi più importanti di vettore atomico sono logico, intero, doppio e carattere. Raw e complex sono usati raramente durante un’analisi dei dati, quindi non li discuterò qui.
20.3.1 Logico
I vettori logici sono il tipo più semplice di vettore atomico perché possono assumere solo tre possibili valori: FALSE, TRUE e NA. I vettori logici sono solitamente costruiti con operatori di confronto, come descritto in [comparatori]. Puoi anche crearli a mano con c():
20.3.2 Numerico
I vettori interi e doppi sono conosciuti collettivamente come vettori numerici. In R, i numeri sono doppi per default. Per fare un intero, metti una L dopo il numero:
La distinzione tra interi e double non è solitamente importante, ma ci sono due importanti differenze di cui dovreste essere consapevoli:
-
I double sono approssimazioni. I double rappresentano numeri in virgola mobile che non possono essere sempre rappresentati con precisione con una quantità fissa di memoria. Questo significa che dovreste considerare tutti i double come approssimazioni. Per esempio, cos’è il quadrato della radice quadrata di due?
x <- sqrt(2) ^ 2 x #> [1] 2 x - 2 #> [1] 4.440892e-16Questo comportamento è comune quando si lavora con i numeri in virgola mobile: la maggior parte calcoli includono qualche errore di approssimazione. Invece di confrontare i numeri in virgola mobile in virgola mobile usando
==, dovreste usaredplyr::near()che permette qualche tolleranza numerica. -
Gli interi hanno un valore speciale:
NA, mentre i double ne hanno quattro:NA,NaN,Infe-Inf. Tutti e tre i valori specialiNaN,Infe-Infpossono presentarsi durante la divisione:c(-1, 0, 1) / 0 #> [1] -Inf NaN InfEvita di usare
==per controllare questi altri valori speciali. Usate invece le funzioni di aiutois.finite(),is.infinite(), eis.nan():0 Inf NA NaN is.finite()x is.infinite()x is.na()x x is.nan()x
20.3.3 Carattere
I vettori di caratteri sono il tipo più complesso di vettore atomico, perché ogni elemento di un vettore di caratteri è una stringa, e una stringa può contenere una quantità arbitraria di dati.
Hai già imparato molto su come lavorare con le stringhe in stringhe. Qui volevo menzionare una caratteristica importante dell’implementazione delle stringhe sottostanti: R usa un pool globale di stringhe. Questo significa che ogni stringa unica è immagazzinata in memoria solo una volta, e ogni uso della stringa punta a quella rappresentazione. Questo riduce la quantità di memoria necessaria alle stringhe duplicate. Potete vedere questo comportamento in pratica con pryr::object_size():
x <- "This is a reasonably long string."
pryr::object_size(x)
#> 152 B
y <- rep(x, 1000)
pryr::object_size(y)
#> 8.14 kBy non occupa 1000 volte più memoria di x, perché ogni elemento di y è solo un puntatore a quella stessa stringa. Un puntatore è di 8 byte, quindi 1000 puntatori a una stringa di 152 B sono 8 * 1000 + 152 = 8.14 kB.
20.3.4 Valori mancanti
Nota che ogni tipo di vettore atomico ha il suo valore mancante:
NA # logical
#> [1] NA
NA_integer_ # integer
#> [1] NA
NA_real_ # double
#> [1] NA
NA_character_ # character
#> [1] NANormalmente non avete bisogno di conoscere questi diversi tipi perché potete sempre usare NA e sarà convertito nel tipo corretto usando le regole di coercizione implicite descritte in seguito. Tuttavia, ci sono alcune funzioni che sono rigide riguardo ai loro input, quindi è utile avere questa conoscenza in tasca in modo da poter essere specifici quando necessario.
20.3.5 Esercizi
Descrivete la differenza tra
is.finite(x)e!is.infinite(x).Leggete il codice sorgente di
dplyr::near()(Suggerimento: per vedere il codice sorgente, eliminate il()). Come funziona?Un vettore logico può assumere 3 possibili valori. Quanti valori possibili valori possibili può assumere un vettore intero? Quanti valori possibili può assumere prendere un double? Usa Google per fare qualche ricerca.
Inventa almeno quattro funzioni che ti permettono di convertire un doppio in un intero. In cosa differiscono? Sii preciso.
Quali funzioni del pacchetto readr ti permettono di trasformare una stringa in un vettore logico, intero e double?
20.4 Usare i vettori atomici
Ora che hai capito i diversi tipi di vettore atomico, è utile rivedere alcuni degli strumenti importanti per lavorare con essi. Questi includono:
Come convertire da un tipo all’altro e quando ciò avviene automaticamente.
Come capire se un oggetto è un tipo specifico di vettore.
Cosa succede quando si lavora con vettori di diversa lunghezza.
Come nominare gli elementi di un vettore.
Come estrarre gli elementi di interesse.
20.4.1 Coercizione
Ci sono due modi per convertire, o coercere, un tipo di vettore in un altro:
La coercizione esplicita avviene quando si chiama una funzione come
as.logical(),as.integer(),as.double(), oas.character(). Ogni volta che vi trovate te di usare la coercizione esplicita, dovresti sempre controllare se è possibile fare la correzione a monte, in modo che il vettore non abbia mai avuto il tipo sbagliato in all’inizio. Per esempio, potrebbe essere necessario modificare la specifica di readrcol_types.La coercizione implicita avviene quando si usa un vettore in un contesto specifico che si aspetta un certo tipo di vettore. Per esempio, quando usate un vettore logico logico con una funzione di riepilogo numerico, o quando si usa un vettore doppio dove ci si aspetta un vettore intero.
Poiché la coercizione esplicita è usata relativamente raramente, ed è in gran parte facile da capire, mi concentrerò sulla coercizione implicita qui.
Avete già visto il tipo più importante di coercizione implicita: usare un vettore logico in un contesto numerico. In questo caso TRUE è convertito in 1 e FALSE convertito in 0. Ciò significa che la somma di un vettore logico è il numero di veri, e la media di un vettore logico è la proporzione di veri:
x <- sample(20, 100, replace = TRUE)
y <- x > 10
sum(y) # quanti sono maggiori di 10?
#> [1] 38
mean(y) # quale proporzione è maggiore di 10?
#> [1] 0.38Potreste vedere del codice (tipicamente più vecchio) che si basa sulla coercizione implicita nella direzione opposta, da intero a logico:
if (length(x)) {
# fa qualcosa
}In questo caso, 0 è convertito in FALSE e tutto il resto è convertito in TRUE. Penso che questo renda più difficile capire il tuo codice, e non lo consiglio. Sii invece esplicito: lunghezza(x) > 0.
È anche importante capire cosa succede quando provate a creare un vettore contenente più tipi con c(): il tipo più complesso vince sempre.
typeof(c(TRUE, 1L))
#> [1] "integer"
typeof(c(1L, 1.5))
#> [1] "double"
typeof(c(1.5, "a"))
#> [1] "character"Un vettore atomico non può avere un mix di tipi diversi perché il tipo è una proprietà del vettore completo, non dei singoli elementi. Se hai bisogno di mescolare più tipi nello stesso vettore, dovresti usare una lista, che imparerai a conoscere tra poco.
20.4.2 Funzioni di test
A volte vuoi fare cose diverse in base al tipo di vettore. Un’opzione è usare typeof(). Un’altra è usare una funzione di test che restituisca un TRUE o un FALSE. Base R fornisce molte funzioni come is.vector() e is.atomic(), ma spesso restituiscono risultati sorprendenti. Invece, è più sicuro usare le funzioni is_* fornite da purrr, che sono riassunte nella tabella qui sotto.
| lgl | int | dbl | chr | list | |
|---|---|---|---|---|---|
is_logical() |
x | ||||
is_integer() |
x | ||||
is_double() |
x | ||||
is_numeric() |
x | x | |||
is_character() |
x | ||||
is_atomic() |
x | x | x | x | |
is_list() |
x | ||||
is_vector() |
x | x | x | x | x |
20.4.3 Scalari e regole di riciclaggio
Oltre a costringere implicitamente i tipi di vettori ad essere compatibili, R costringerà implicitamente anche la lunghezza dei vettori. Questo è chiamato riciclo dei vettori, perché il vettore più corto viene ripetuto, o riciclato, alla stessa lunghezza del vettore più lungo.
Questo è generalmente più utile quando si mescolano vettori e “scalari”. Ho messo gli scalari tra virgolette perché R in realtà non ha scalari: invece, un singolo numero è un vettore di lunghezza 1. Poiché non ci sono scalari, la maggior parte delle funzioni built-in sono vettorizzate, il che significa che opereranno su un vettore di numeri. Ecco perché, per esempio, questo codice funziona:
sample(10) + 100
#> [1] 107 104 103 109 102 101 106 110 105 108
runif(10) > 0.5
#> [1] FALSE TRUE FALSE FALSE TRUE TRUE TRUE TRUE TRUE TRUEIn R, le operazioni matematiche di base lavorano con i vettori. Ciò significa che non dovreste mai aver bisogno di eseguire un’iterazione esplicita quando eseguite semplici calcoli matematici.
È intuitivo ciò che dovrebbe accadere se si aggiungono due vettori della stessa lunghezza, o un vettore e uno “scalare”, ma cosa succede se si aggiungono due vettori di lunghezza diversa?
1:10 + 1:2
#> [1] 2 4 4 6 6 8 8 10 10 12Qui, R espanderà il vettore più breve alla stessa lunghezza del più lungo, il cosiddetto riciclo. Questo è silenzioso tranne quando la lunghezza del più lungo non è un multiplo intero della lunghezza del più corto:
1:10 + 1:3Mentre il riciclo vettoriale può essere usato per creare codice molto succinto e intelligente, può anche nascondere silenziosamente dei problemi. Per questo motivo, le funzioni vettoriali di tidyverse daranno errore quando si ricicla qualcosa che non sia uno scalare. Se volete riciclare, dovrete farlo voi stessi con rep():
tibble(x = 1:4, y = 1:2)
#> Error:
#> ! Tibble columns must have compatible sizes.
#> • Size 4: Existing data.
#> • Size 2: Column `y`.
#> ℹ Only values of size one are recycled.
tibble(x = 1:4, y = rep(1:2, 2))
#> # A tibble: 4 × 2
#> x y
#> <int> <int>
#> 1 1 1
#> 2 2 2
#> 3 3 1
#> 4 4 2
tibble(x = 1:4, y = rep(1:2, each = 2))
#> # A tibble: 4 × 2
#> x y
#> <int> <int>
#> 1 1 1
#> 2 2 1
#> 3 3 2
#> 4 4 220.4.4 Denominazione dei vettori
Tutti i tipi di vettori possono essere nominati. Puoi nominarli durante la creazione con c():
c(x = 1, y = 2, z = 4)
#> x y z
#> 1 2 4O dopo averlo fatto, con purrr::set_names():
I vettori nominati sono molto utili per il subsetting, descritto di seguito.
20.4.5 Sottoinsiemi
Finora abbiamo usato dplyr::filter() per filtrare le righe in una tibla. Il filtro() funziona solo con le tibbie, quindi avremo bisogno di un nuovo strumento per i vettori: [. [ è la funzione di sottoinsieme, e si chiama come x[a]. Ci sono quattro tipi di cose con cui è possibile subsettare un vettore:
-
Un vettore numerico contenente solo numeri interi. I numeri interi devono essere o tutti positivi, tutti negativi o zero.
Il sottoinsieme con i numeri interi positivi mantiene gli elementi in quelle posizioni:
Ripetendo una posizione, si può effettivamente fare un output più lungo dell’input:
x[c(1, 1, 5, 5, 5, 2)] #> [1] "one" "one" "five" "five" "five" "two"I valori negativi fanno cadere gli elementi nelle posizioni specificate:
x[c(-1, -3, -5)] #> [1] "two" "four"È un errore mischiare valori positivi e negativi:
x[c(1, -1)] #> Error in x[c(1, -1)]: only 0's may be mixed with negative subscriptsIl messaggio di errore menziona il subsetting con zero, che non restituisce alcun valore:
x[0] #> character(0)Questo non è utile molto spesso, ma può essere utile se volete creare strutture di dati insolite con cui testare le vostre funzioni.
-
Il sottoinsieme con un vettore logico mantiene tutti i valori corrispondenti ad un valore
TRUE. Questo è più spesso utile in combinazione con le funzioni di confronto. -
Se avete un vettore di nome, potete sottoinvestirlo con un vettore di caratteri:
Come con gli interi positivi, potete anche usare un vettore di caratteri per duplicare singole voci.
Il tipo più semplice di sottoinsieme è il nulla,
x[], che restituisce il completox. Questo non è utile per il sottoinsieme di vettori, ma è utile quando si sottopongono matrici (e altre strutture ad alta dimensione) perché permette di selezionare tutte le righe o tutte le colonne, lasciando indice vuoto. Per esempio, sexè 2d,x[1, ]seleziona la prima riga e tutte le colonne, ex[, -1]seleziona tutte le righe e tutte le colonne tranne la prima.
Per saperne di più sulle applicazioni del subsetting, leggete il capitolo “Subsetting” di Advanced R: http://adv-r.had.co.nz/Subsetting.html#applications.
C’è un’importante variazione di [ chiamata [[. [[ estrae sempre e solo un singolo elemento, e abbandona sempre i nomi. È una buona idea usarla ogni volta che volete rendere chiaro che state estraendo un singolo elemento, come in un ciclo for. La distinzione tra [ e [[ è più importante per le liste, come vedremo tra poco.
20.4.6 Esercizi
Cosa ti dice il
mean(is.na(x))di un vettorex? 2. Che dire disum(!is.finite(x))?Leggete attentamente la documentazione di
is.vector(). Cosa verifica effettivamente verifica? Perchéis.atomic()non concorda con la definizione di vettori atomici di cui sopra?Confronta e contrasta
setNames()conpurrr::set_names().-
Creare funzioni che prendono un vettore come input e restituiscono:
L’ultimo valore. Dovreste usare
[o[[?Gli elementi nelle posizioni pari.
Ogni elemento tranne l’ultimo valore.
Solo i numeri pari (e nessun valore mancante).
Perché
x[-che(x > 0)]non è lo stesso dix[x <= 0]?Cosa succede quando si sottoinveste con un numero intero positivo più grande della lunghezza del vettore? Cosa succede quando si effettua un sottoinsieme con un nome che non esiste?
20.5 Vettori ricorsivi (liste)
Le liste sono un passo avanti nella complessità rispetto ai vettori atomici, perché le liste possono contenere altre liste. Questo le rende adatte a rappresentare strutture gerarchiche o ad albero. Si crea una lista con list():
x <- list(1, 2, 3)
x
#> [[1]]
#> [1] 1
#>
#> [[2]]
#> [1] 2
#>
#> [[3]]
#> [1] 3Uno strumento molto utile per lavorare con le liste è str() perché si concentra sulla struttura, non sul contenuto.
str(x)
#> List of 3
#> $ : num 1
#> $ : num 2
#> $ : num 3
x_named <- list(a = 1, b = 2, c = 3)
str(x_named)
#> List of 3
#> $ a: num 1
#> $ b: num 2
#> $ c: num 3A differenza dei vettori atomici, list() può contenere un mix di oggetti:
y <- list("a", 1L, 1.5, TRUE)
str(y)
#> List of 4
#> $ : chr "a"
#> $ : int 1
#> $ : num 1.5
#> $ : logi TRUELe liste possono anche contenere altre liste!
z <- list(list(1, 2), list(3, 4))
str(z)
#> List of 2
#> $ :List of 2
#> ..$ : num 1
#> ..$ : num 2
#> $ :List of 2
#> ..$ : num 3
#> ..$ : num 420.5.1 Visualizzazione delle liste
Per spiegare le funzioni di manipolazione delle liste più complicate, è utile avere una rappresentazione visiva delle liste. Per esempio, prendete queste tre liste:
Li disegnerò come segue:
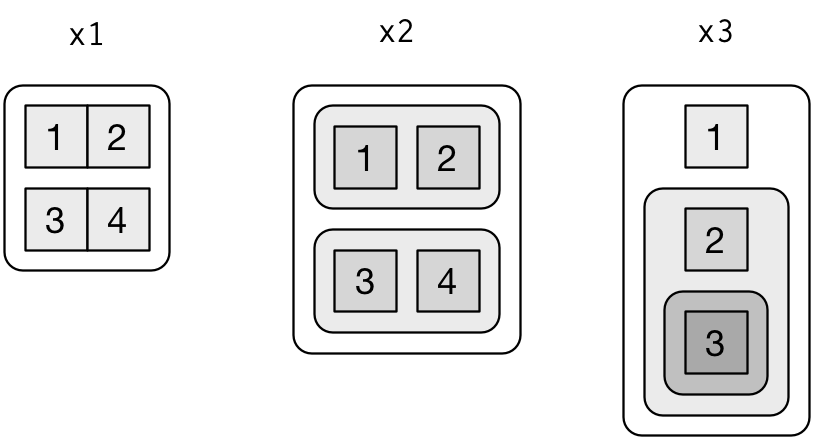
Ci sono tre principi:
Le liste hanno angoli arrotondati. I vettori atomici hanno angoli quadrati.
I figli sono disegnati all’interno del loro genitore e hanno uno sfondo sfondo per rendere più facile vedere la gerarchia.
L’orientamento dei figli (cioè righe o colonne) non è importante, quindi sceglierò un orientamento di riga o di colonna per risparmiare spazio o per illustrare una proprietà importante nell’esempio.
20.5.2 Sottoinsieme
Ci sono tre modi per suddividere una lista, che illustrerò con una lista chiamata a:
-
[estrae una sotto-lista. Il risultato sarà sempre una lista.str(a[1:2]) #> List of 2 #> $ a: int [1:3] 1 2 3 #> $ b: chr "a string" str(a[4]) #> List of 1 #> $ d:List of 2 #> ..$ : num -1 #> ..$ : num -5Come con i vettori, potete sottoporre a subset un vettore logico, intero o di caratteri.
-
[[estrae un singolo componente da una lista. Rimuove un livello di gerarchia dalla lista. -
$è un’abbreviazione per estrarre elementi nominati di una lista. Funziona in modo simile a[[eccetto che non c’è bisogno di usare le virgolette.a$a #> [1] 1 2 3 a[["a"]] #> [1] 1 2 3
La distinzione tra [ e [[ è davvero importante per le liste, perché [[ si addentra nella lista mentre [ restituisce una nuova lista più piccola. Confrontate il codice e l’output di cui sopra con la rappresentazione visiva nella figura 20.2.
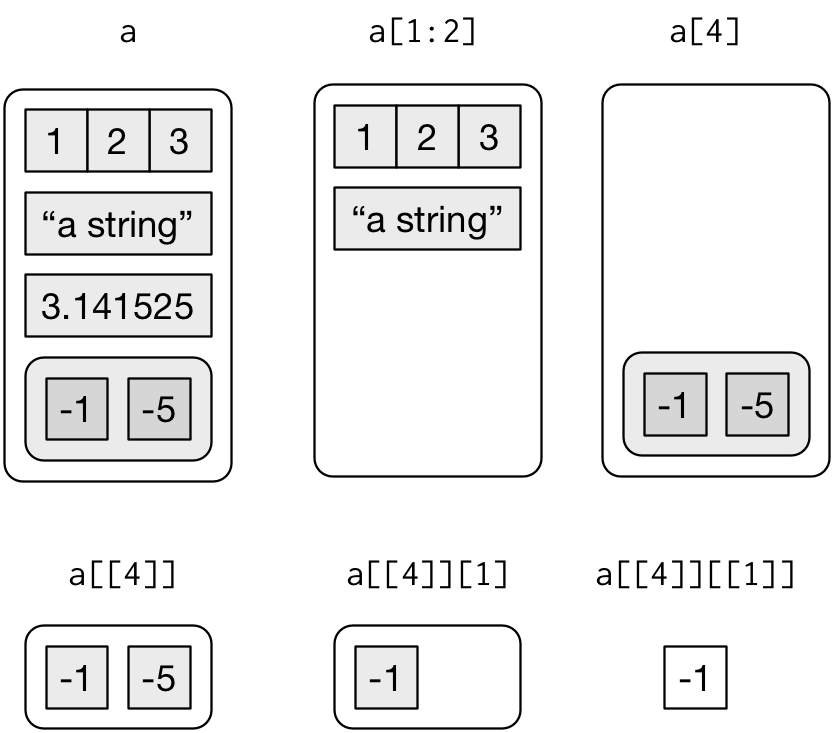
Figure 20.2: Subsetting a list, visually.
20.5.3 Liste di condimenti
La differenza tra [ e [[ è molto importante, ma è facile confondersi. Per aiutarti a ricordare, lascia che ti mostri un insolito saliera per il pepe.
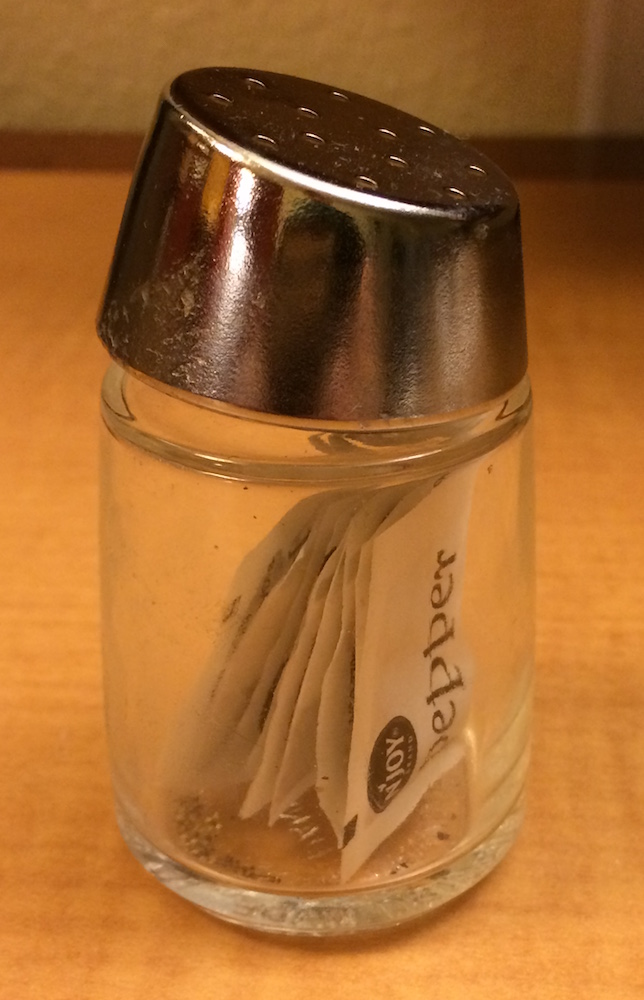
Se questa saliera di pepe è la vostra lista x, allora, x[1] è una saliera di pepe contenente un singolo pacchetto di pepe:
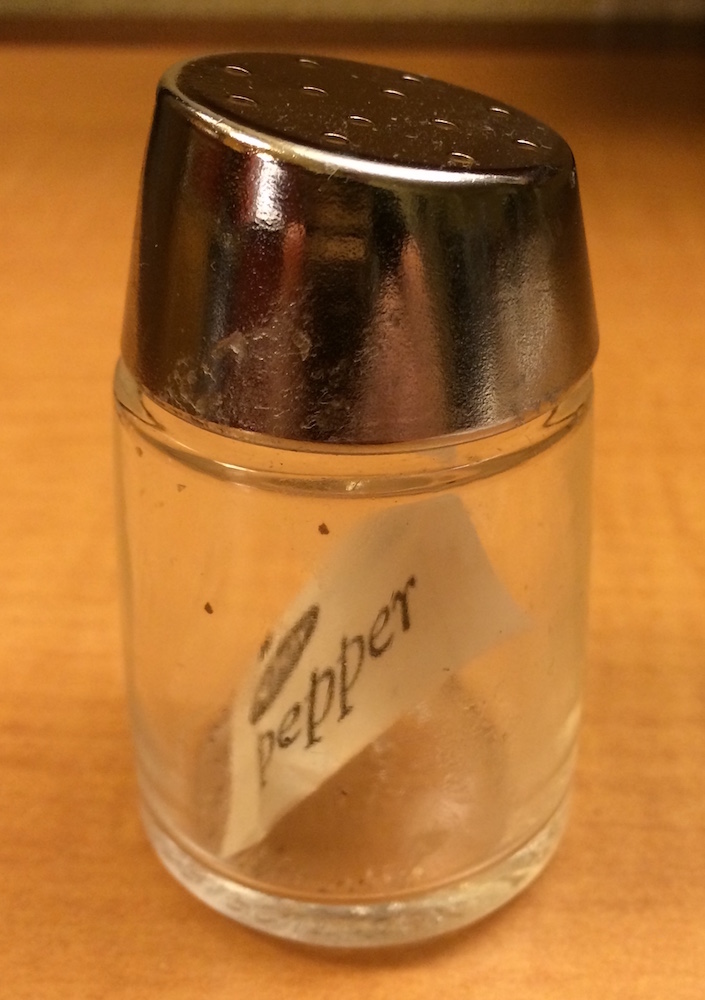
x[2] avrebbe lo stesso aspetto, ma conterrebbe il secondo pacchetto. x[1:2] sarebbe una saliera per il pepe contenente due pacchetti di pepe.
x[[1]] è:

Se voleste ottenere il contenuto del pacchetto pepper, avreste bisogno di x[[1]][[1]]:

20.6 Attributi
Ogni vettore può contenere metadati aggiuntivi arbitrari attraverso i suoi attributes. Puoi pensare agli attributi come a una lista di vettori denominata che può essere allegata a qualsiasi oggetto.
Potete ottenere e impostare i valori dei singoli attributi con attr() o vederli tutti insieme con attributes().
x <- 1:10
attr(x, "greeting")
#> NULL
attr(x, "greeting") <- "Hi!"
attr(x, "farewell") <- "Bye!"
attributes(x)
#> $greeting
#> [1] "Hi!"
#>
#> $farewell
#> [1] "Bye!"Ci sono tre attributi molto importanti che vengono utilizzati per implementare parti fondamentali di R:
- Names sono usati per nominare gli elementi di un vettore. 1. 2. Dimensions (dims, in breve) fanno sì che un vettore si comporti come una matrice o un array. 1. Class è usato per implementare il sistema orientato agli oggetti S3.
Avete visto i nomi sopra, e non parleremo di dimensioni perché non usiamo matrici in questo libro. Resta da descrivere la classe, che controlla il funzionamento delle funzioni generiche. Le funzioni generiche sono la chiave per la programmazione orientata agli oggetti in R, perché fanno sì che le funzioni si comportino diversamente per diverse classi di input. Una discussione dettagliata della programmazione orientata agli oggetti va oltre lo scopo di questo libro, ma potete leggerne di più in Advanced R a http://adv-r.had.co.nz/OO-essentials.html#s3.
Ecco come appare una tipica funzione generica:
as.Date
#> function (x, ...)
#> UseMethod("as.Date")
#> <bytecode: 0x55a5b039ed00>
#> <environment: namespace:base>La chiamata a “UseMethod” significa che questa è una funzione generica, e chiamerà uno specifico method, una funzione, basata sulla classe del primo argomento. (Tutti i metodi sono funzioni; non tutte le funzioni sono metodi). Potete elencare tutti i metodi di un generico con metodi():
methods("as.Date")
#> [1] as.Date.character as.Date.default as.Date.factor
#> [4] as.Date.numeric as.Date.POSIXct as.Date.POSIXlt
#> [7] as.Date.vctrs_sclr* as.Date.vctrs_vctr*
#> see '?methods' for accessing help and source codePer esempio, se x è un vettore di caratteri, as.Date() chiamerà as.Date.character(); se è un fattore, chiamerà as.Date.factor().
Potete vedere l’implementazione specifica di un metodo con getS3method():
getS3method("as.Date", "default")
#> function (x, ...)
#> {
#> if (inherits(x, "Date"))
#> x
#> else if (is.null(x))
#> .Date(numeric())
#> else if (is.logical(x) && all(is.na(x)))
#> .Date(as.numeric(x))
#> else stop(gettextf("do not know how to convert '%s' to class %s",
#> deparse1(substitute(x)), dQuote("Date")), domain = NA)
#> }
#> <bytecode: 0x55a5adecfed0>
#> <environment: namespace:base>
getS3method("as.Date", "numeric")
#> function (x, origin, ...)
#> {
#> if (missing(origin)) {
#> if (!length(x))
#> return(.Date(numeric()))
#> if (!any(is.finite(x)))
#> return(.Date(x))
#> stop("'origin' must be supplied")
#> }
#> as.Date(origin, ...) + x
#> }
#> <bytecode: 0x55a5aded6140>
#> <environment: namespace:base>Il più importante generico S3 è print(): controlla come l’oggetto viene stampato quando si digita il suo nome sulla console. Altri generici importanti sono le funzioni di subsetting [, [[, e $.
20.7 Vettori incrementati
I vettori atomici e le liste sono i mattoni per altri importanti tipi di vettori come i fattori e le date. Li chiamo vettori aumentati, perché sono vettori con ulteriori attributi, inclusa la classe. Poiché i vettori aumentati hanno una classe, si comportano diversamente dal vettore atomico su cui sono costruiti. In questo libro, facciamo uso di quattro importanti vettori aumentati:
- Fattori
- Date
- Data-ora
- Tibble
Questi sono descritti di seguito.
20.7.1 Fattori
I fattori sono progettati per rappresentare dati categorici che possono assumere un insieme fisso di possibili valori. I fattori sono costruiti sopra gli interi e hanno un attributo levels:
x <- factor(c("ab", "cd", "ab"), levels = c("ab", "cd", "ef"))
typeof(x)
#> [1] "integer"
attributes(x)
#> $levels
#> [1] "ab" "cd" "ef"
#>
#> $class
#> [1] "factor"20.7.2 Date e data-ora
Le date in R sono vettori numerici che rappresentano il numero di giorni dal 1° gennaio 1970.
x <- as.Date("1971-01-01")
unclass(x)
#> [1] 365
typeof(x)
#> [1] "double"
attributes(x)
#> $class
#> [1] "Date"I data-ora sono vettori numerici con classe POSIXct che rappresentano il numero di secondi dal 1 gennaio 1970. (Nel caso ve lo steste chiedendo, “POSIXct” sta per “Portable Operating System Interface”, ora del calendario).
x <- lubridate::ymd_hm("1970-01-01 01:00")
unclass(x)
#> [1] 3600
#> attr(,"tzone")
#> [1] "UTC"
typeof(x)
#> [1] "double"
attributes(x)
#> $class
#> [1] "POSIXct" "POSIXt"
#>
#> $tzone
#> [1] "UTC"L’attributo tzone è opzionale. Controlla come viene stampata l’ora, non a quale ora assoluta si riferisce.
attr(x, "tzone") <- "US/Pacific"
x
#> [1] "1969-12-31 17:00:00 PST"
attr(x, "tzone") <- "US/Eastern"
x
#> [1] "1969-12-31 20:00:00 EST"C’è un altro tipo di date-times chiamato POSIXlt. Questi sono costruiti sopra le liste con nome:
y <- as.POSIXlt(x)
typeof(y)
#> [1] "list"
attributes(y)
#> $names
#> [1] "sec" "min" "hour" "mday" "mon" "year" "wday" "yday"
#> [9] "isdst" "zone" "gmtoff"
#>
#> $class
#> [1] "POSIXlt" "POSIXt"
#>
#> $tzone
#> [1] "US/Eastern" "EST" "EDT"I POSIXlts sono rari all’interno del tidyverse. Spuntano fuori in R di base, perché sono necessari per estrarre componenti specifici di una data, come l’anno o il mese. Dato che lubridate fornisce degli helper per fare questo, non ne avete bisogno. I POSIXct sono sempre più facili da lavorare, quindi se scoprite di avere un POSIXlt, dovreste sempre convertirlo in un normale data time lubridate::as_date_time().
20.7.3 Tibble
Le tibble sono liste aumentate: hanno classe “tbl_df” + “tbl” + “data.frame”, e gli attributi names (colonna) e row.names:
tb <- tibble::tibble(x = 1:5, y = 5:1)
typeof(tb)
#> [1] "list"
attributes(tb)
#> $class
#> [1] "tbl_df" "tbl" "data.frame"
#>
#> $row.names
#> [1] 1 2 3 4 5
#>
#> $names
#> [1] "x" "y"La differenza tra una tibble e una lista è che tutti gli elementi di un data frame devono essere vettori della stessa lunghezza. Tutte le funzioni che lavorano con le tibble impongono questo vincolo.
I data.frame tradizionali hanno una struttura molto simile:
df <- data.frame(x = 1:5, y = 5:1)
typeof(df)
#> [1] "list"
attributes(df)
#> $names
#> [1] "x" "y"
#>
#> $class
#> [1] "data.frame"
#>
#> $row.names
#> [1] 1 2 3 4 5La differenza principale è la classe. La classe di tibble include “data.frame”, il che significa che le tibble ereditano il comportamento dei normali data frame per default.
20.7.4 Esercizi
Cosa restituisce
hms::hms(3600)? Come si stampa? Quale primitiva è costruito sopra il vettore aumentato? Quali attributi usa usa?Prova a fare un tibbo che abbia colonne di lunghezza diversa. Cosa succede?
In base alla definizione di cui sopra, va bene avere una lista come colonna di una tibla?