27 R Markdown
27.1 Introduzione
R Markdown fornisce un framework di authoring unificato per la scienza dei dati, che combina il codice, i risultati e i commenti in prosa. I documenti R Markdown sono completamente riproducibili e supportano decine di formati di output, come PDF, file Word, presentazioni e altro ancora.
I file R Markdown sono progettati per essere utilizzati in tre modi:
Per comunicare ai decisori, che vogliono concentrarsi sulle conclusioni, non sul codice che sta dietro l’analisi.
Per collaborare con altri data scientist (compreso il futuro te stesso!), che sono interessati sia alle vostre conclusioni che al modo in cui le avete elaborate. che sono interessati sia alle vostre conclusioni che al modo in cui le avete raggiunte (cioè il codice). il codice).
Come ambiente in cui “fare” scienza dei dati, come un moderno taccuino di laboratorio di laboratorio dove è possibile registrare non solo ciò che si è fatto, ma anche ciò che si è pensato. pensiero.
R Markdown integra una serie di pacchetti R e di strumenti esterni. Ciò significa che l’aiuto non è in genere disponibile attraverso ?. Invece, mentre lavorate a questo capitolo e utilizzate R Markdown in futuro, tenete a portata di mano queste risorse:
R Markdown Cheat Sheet: Help > Cheatsheets > R Markdown Cheat Sheet,
Guida di riferimento a R Markdown: Help > Cheatsheets > R Markdown Reference Guide. Guida_.
Entrambi i fogli informativi sono disponibili anche all’indirizzo https://rstudio.com/resources/cheatsheets/.
27.2 Nozioni di base di R Markdown
Questo è un file R Markdown, un file di testo semplice con estensione .Rmd:
---
title: "Diamond sizes"
date: 2016-08-25
output: html_document
---
```{r setup, include = FALSE}
library(ggplot2)
library(dplyr)
smaller <- diamonds %>%
filter(carat <= 2.5)
```
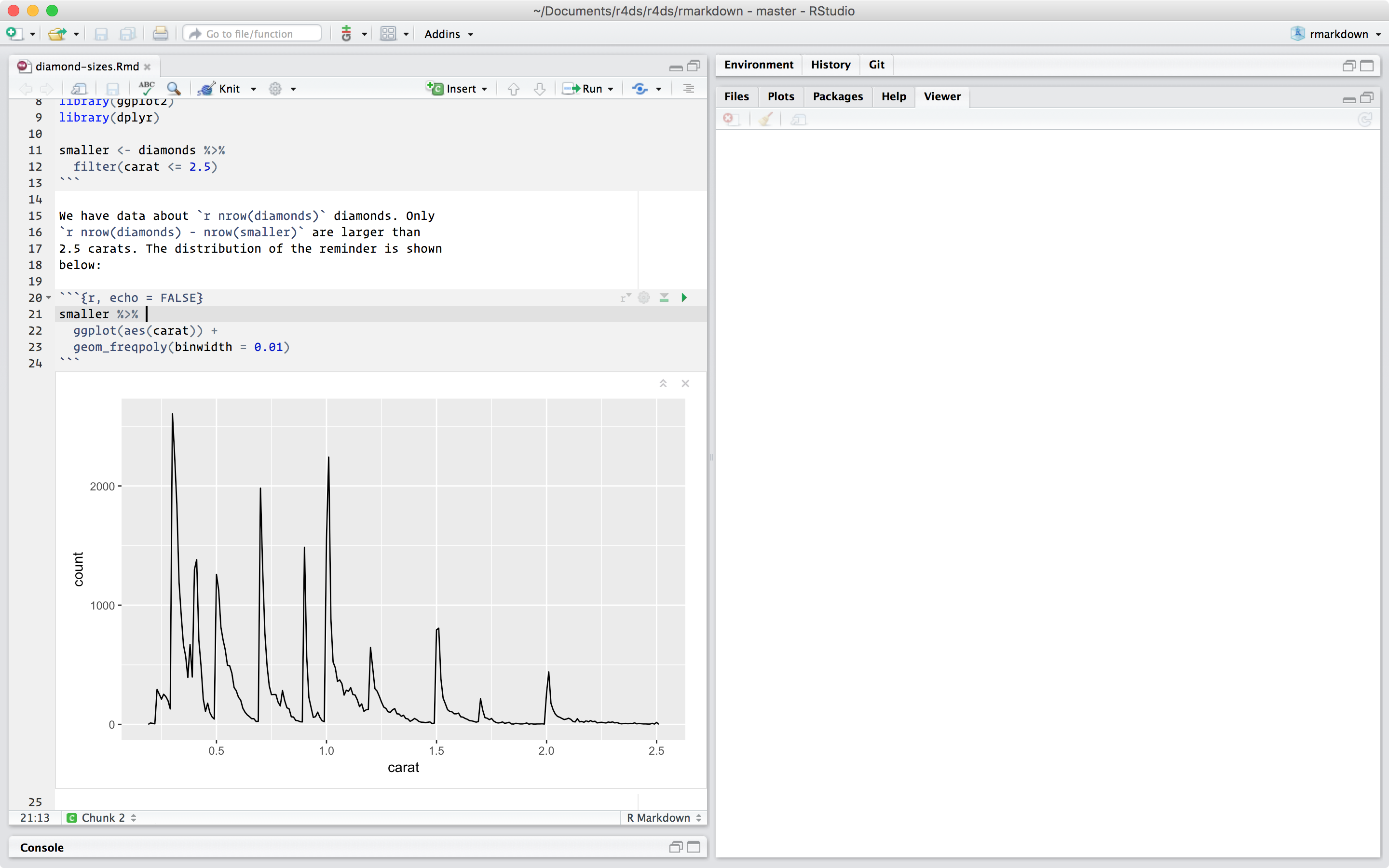
We have data about `r nrow(diamonds)` diamonds. Only
`r nrow(diamonds) - nrow(smaller)` are larger than
2.5 carats. The distribution of the remainder is shown
below:
```{r, echo = FALSE}
smaller %>%
ggplot(aes(carat)) +
geom_freqpoly(binwidth = 0.01)
```Contiene tre importanti tipi di contenuti:
- Un’intestazione (opzionale) __YAML circondata da
---s. -
Chunks di codice R circondati da
```. - Testo mescolato con una semplice formattazione del testo come
# headinge_italics_.
Quando si apre un `.Rmd’, si ottiene un’interfaccia di blocco note in cui il codice e l’output sono interlacciati. È possibile eseguire ciascun pezzo di codice facendo clic sull’icona Esegui (simile a un pulsante di riproduzione nella parte superiore del pezzo) o premendo Cmd/Ctrl + Maiusc + Invio. RStudio esegue il codice e visualizza i risultati in linea con il codice:
Per produrre un rapporto completo contenente tutto il testo, il codice e i risultati, fare clic su “Knit” o premere Cmd/Ctrl + Shift + K. È possibile farlo anche in modo programmatico con rmarkdown::render("1-example.Rmd"). In questo modo si visualizza il rapporto nel riquadro del visualizzatore e si crea un file HTML autonomo che si può condividere con altri.
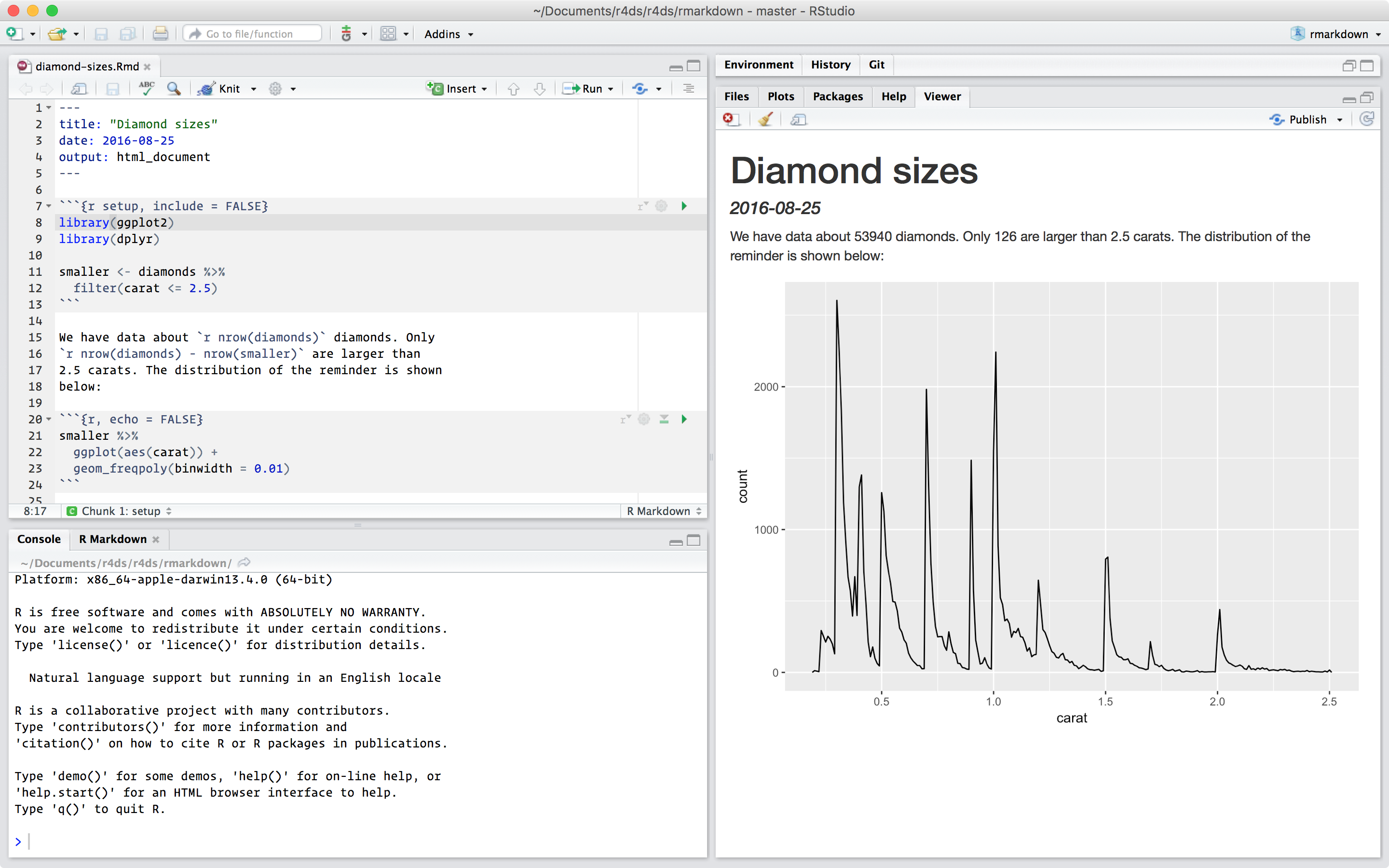
Quando si knit il documento, R Markdown invia il file .Rmd a knitr, http://yihui.name/knitr/, che esegue tutti i pezzi di codice e crea un nuovo documento markdown (.md) che include il codice e il suo output. Il file markdown generato da knitr viene poi elaborato da pandoc, http://pandoc.org/, che è responsabile della creazione del file finito. Il vantaggio di questo flusso di lavoro in due fasi è che si può creare un’ampia gamma di formati di output, come si vedrà in Formati di R markdown.

Per iniziare a creare il proprio file `.Rmd’, selezionare File > New File > R Markdown… nella barra dei menu. RStudio lancerà una procedura guidata che potrete utilizzare per pre-popolare il vostro file con contenuti utili che vi ricorderanno come funzionano le caratteristiche principali di R Markdown.
Le sezioni seguenti approfondiscono i tre componenti di un documento R Markdown: il testo markdown, i pezzi di codice e l’intestazione YAML.
27.2.1 Esercizi
Creare un nuovo blocco note utilizzando File > New File > R Notebook. Leggere le istruzioni. Esercitatevi a eseguire i pezzi. Verificare che sia possibile modificare il codice, eseguirlo nuovamente e vedere l’output modificato.
Create un nuovo documento R Markdown con File > New File > R Markdown…. Lavorare a maglia facendo clic sul pulsante appropriato. Lavorare con la scorciatoia da tastiera appropriata. tastiera appropriata. Verificare che sia possibile modificare l’input e vedere l’aggiornamento dell’output.
Confrontate e confrontate i file R notebook e R markdown creati in precedenza. sopra. In che modo gli output sono simili? In che modo sono diversi? Come sono gli input sono simili? In che modo sono diversi? Cosa succede se copiare l’intestazione YAML da uno all’altro?
Creare un nuovo documento R Markdown per ognuno dei tre formati incorporati formati incorporati: HTML, PDF e Word. Lavorate a maglia ciascuno dei tre documenti. In che modo l’output differisce? In cosa differisce l’input? (Potrebbe essere necessario installare LaTeX per creare l’output PDF — RStudio vi chiederà se è necessario). vi chiederà se ciò è necessario).
27.3 Formattazione del testo con Markdown
La prosa nei file .Rmd è scritta in Markdown, un insieme leggero di convenzioni per la formattazione dei file di testo. Markdown è stato progettato per essere facile da leggere e da scrivere. È anche molto facile da imparare. La guida che segue mostra come utilizzare il Markdown di Pandoc, una versione leggermente estesa di Markdown che R Markdown comprende.
Text formatting
------------------------------------------------------------
*italic* or _italic_
**bold** __bold__
`code`
superscript^2^ and subscript~2~
Headings
------------------------------------------------------------
# 1st Level Header
## 2nd Level Header
### 3rd Level Header
Lists
------------------------------------------------------------
* Bulleted list item 1
* Item 2
* Item 2a
* Item 2b
1. Numbered list item 1
1. Item 2. The numbers are incremented automatically in the output.
Links and images
------------------------------------------------------------
<http://example.com>
[linked phrase](http://example.com)

Tables
------------------------------------------------------------
First Header | Second Header
------------- | -------------
Content Cell | Content Cell
Content Cell | Content CellIl modo migliore per impararle è semplicemente provarle. Ci vorrà qualche giorno, ma presto diventeranno una seconda natura e non sarà più necessario pensarci. In caso di dimenticanza, è possibile accedere a un pratico foglio di riferimento con Help > Markdown Quick Reference.
27.3.1 Esercizi
Mettete in pratica quanto appreso creando un breve curriculum vitae. Il titolo dovrebbe essere il vostro nome, e dovreste includere titoli per (almeno) l’istruzione o l’impiego. occupazione. Ciascuna delle sezioni deve includere un elenco puntato di lavori/diplomi. Evidenziate l’anno in grassetto.
-
Utilizzando la guida rapida di R Markdown, capire come fare:
- Aggiungere una nota a piè di pagina.
- Aggiungere una regola orizzontale.
- Aggiungere una citazione a blocchi.
Copiare e incollare il contenuto di
diamond-sizes.Rmdda https://github.com/hadley/r4ds/tree/master/rmarkdown in un documento R in un documento markdown locale. Verificate che sia possibile eseguirlo, quindi aggiungete del testo dopo il poligono di frequenza che descrive le sue caratteristiche più evidenti.
27.4 Pezzi di codice
Per eseguire del codice all’interno di un documento R Markdown, è necessario inserire un chunk. Ci sono tre modi per farlo:
La scorciatoia da tastiera Cmd/Ctrl + Alt + I
L’icona del pulsante “Inserisci” nella barra degli strumenti dell’editor.
Digitando manualmente i delimitatori di pezzi
```{r}e```.
Ovviamente, vi consiglio di imparare la scorciatoia da tastiera. Vi farà risparmiare molto tempo nel lungo periodo!
Potete continuare a eseguire il codice utilizzando la scorciatoia da tastiera che ormai (spero!) conoscete e amate: Cmd/Ctrl + Invio. Tuttavia, i chunk hanno una nuova scorciatoia da tastiera: Cmd/Ctrl + Shift + Invio, che esegue tutto il codice contenuto nel gruppo. Pensate a un gruppo come a una funzione. Un chunk dovrebbe essere relativamente autonomo e focalizzato su un singolo compito.
Le sezioni seguenti descrivono l’intestazione del chunk, che consiste in ```{r, seguito da un nome opzionale del chunk, seguito da opzioni separate da virgole, seguite da }. Segue il codice R e la fine del chunk è indicata da un ultimo ```.
27.4.1 Nome del chunk
Ai chunk può essere dato un nome opzionale: ```{r by-name}. Questo ha tre vantaggi:
-
Si può navigare più facilmente verso specifici chunk usando il navigatore di codice a discesa in basso a sinistra. navigatore di codice in basso a sinistra nell’editor di script:
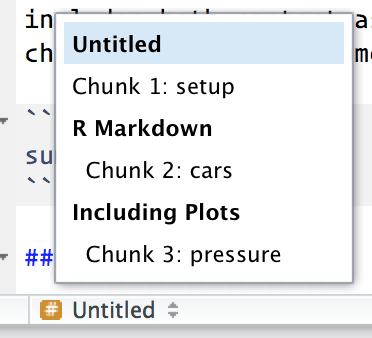
I grafici prodotti dai chunks avranno nomi utili che li renderanno più facili da usare altrove. Maggiori informazioni in altre opzioni importanti.
È possibile impostare reti di pezzi memorizzati nella cache per evitare di rieseguire costose calcoli costosi a ogni esecuzione. Per saperne di più, si veda più avanti.
C’è un nome di chunk che implica un comportamento speciale: setup. Quando si è in modalità notebook, il chunk chiamato setup viene eseguito automaticamente una volta, prima che venga eseguito qualsiasi altro codice.
27.4.2 Opzioni dei chunk
L’output dei chunk può essere personalizzato con le opzioni, argomenti forniti all’intestazione dei chunk. Knitr fornisce quasi 60 opzioni che possono essere utilizzate per personalizzare i chunk di codice. In questa sede tratteremo le opzioni più importanti, che verranno utilizzate di frequente. L’elenco completo è disponibile all’indirizzo http://yihui.name/knitr/options/.
L’insieme più importante di opzioni controlla se il blocco di codice viene eseguito e quali risultati vengono inseriti nel report finito:
eval = FALSEimpedisce che il codice venga valutato. (E ovviamente se il codice codice non viene eseguito, non verrà generato alcun risultato). Questo è utile per visualizzare un esempio di codice, o per disabilitare un grande blocco di codice senza commentare ogni riga.include = FALSEesegue il codice, ma non mostra il codice o i risultati nel documento finale. nel documento finale. Usare questa opzione per il codice di configurazione che non si vuole ingombrare il rapporto.echo = FALSEimpedisce al codice, ma non ai risultati, di apparire nel file finale. file finito. Usare questa opzione quando si scrivono rapporti destinati a persone che non vogliono non vogliono vedere il codice R sottostante.messaggio = FALSEoavvertimento = FALSEimpedisce che i messaggi o gli avvertimenti di apparire nel file finito.risultati = 'hide'nasconde l’output stampato;fig.show = 'hide'nasconde i trame.error = TRUEfa sì che il rendering continui anche se il codice restituisce un errore. Questo è raramente qualcosa che si vuole includere nella versione finale del report. del report, ma può essere molto utile se si ha la necessità di eseguire il debug di ciò che cosa sta succedendo all’interno di.Rmd. È anche utile se si sta insegnando R e si vuole includere deliberatamente un errore. L’impostazione predefinita,errore = FALSO, fa sì che fa sì che il knitting fallisca se c’è un singolo errore nel documento.
La tabella seguente riassume i tipi di output che ciascuna opzione sopprime:
| Option | Run code | Show code | Output | Plots | Messages | Warnings |
|---|---|---|---|---|---|---|
eval = FALSE |
- | - | - | - | - | |
include = FALSE |
- | - | - | - | - | |
echo = FALSE |
- | |||||
results = "hide" |
- | |||||
fig.show = "hide" |
- | |||||
message = FALSE |
- | |||||
warning = FALSE |
- |
27.4.3 Tabelle
Per impostazione predefinita, R Markdown stampa frame e matrici di dati come li vedreste nella console:
mtcars[1:5, ]
#> mpg cyl disp hp drat wt qsec vs am gear carb
#> Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
#> Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
#> Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
#> Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
#> Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2Se si preferisce che i dati siano visualizzati con una formattazione aggiuntiva, si può usare la funzione knitr::kable. Il codice seguente genera la tabella 27.1.
knitr::kable(
mtcars[1:5, ],
caption = "A knitr kable."
)| mpg | cyl | disp | hp | drat | wt | qsec | vs | am | gear | carb | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mazda RX4 | 21.0 | 6 | 160 | 110 | 3.90 | 2.620 | 16.46 | 0 | 1 | 4 | 4 |
| Mazda RX4 Wag | 21.0 | 6 | 160 | 110 | 3.90 | 2.875 | 17.02 | 0 | 1 | 4 | 4 |
| Datsun 710 | 22.8 | 4 | 108 | 93 | 3.85 | 2.320 | 18.61 | 1 | 1 | 4 | 1 |
| Hornet 4 Drive | 21.4 | 6 | 258 | 110 | 3.08 | 3.215 | 19.44 | 1 | 0 | 3 | 1 |
| Hornet Sportabout | 18.7 | 8 | 360 | 175 | 3.15 | 3.440 | 17.02 | 0 | 0 | 3 | 2 |
Si legga la documentazione di ?knitr::kable per vedere gli altri modi in cui si può personalizzare la tabella. Per una personalizzazione ancora più profonda, considerate i pacchetti xtable, stargazer, pander, tables e ascii. Ognuno di essi fornisce una serie di strumenti per restituire tabelle formattate da codice R.
Esiste anche una ricca serie di opzioni per controllare il modo in cui le figure vengono incorporate. Queste opzioni sono illustrate in [salvare le trame].
27.4.4 Caching
Normalmente, ogni maglia di un documento parte da una base completamente pulita. Questo è ottimo per la riproducibilità, perché assicura che ogni calcolo importante sia stato catturato nel codice. Tuttavia, può essere doloroso se si hanno alcuni calcoli che richiedono molto tempo. La soluzione è cache = TRUE. Se impostata, questa opzione salva l’output del chunk in un file su disco con un nome speciale. Nelle esecuzioni successive, knitr controllerà se il codice è cambiato e, in caso contrario, riutilizzerà i risultati in cache.
Il sistema di cache deve essere usato con attenzione, perché per impostazione predefinita si basa solo sul codice, non sulle sue dipendenze. Per esempio, qui il chunk processed_data dipende dal chunk raw_data:
```{r raw_data}
rawdata <- readr::read_csv("a_very_large_file.csv")
```
```{r processed_data, cache = TRUE}
processed_data <- rawdata %>%
filter(!is.na(import_var)) %>%
mutate(new_variable = complicated_transformation(x, y, z))
```Mettere in cache il chunk processed_data significa che verrà rieseguito se la pipeline di dplyr viene modificata, ma non verrà rieseguito se la chiamata read_csv() cambia. È possibile evitare questo problema con l’opzione chunk dependson:
```{r processed_data, cache = TRUE, dependson = "raw_data"}
processed_data <- rawdata %>%
filter(!is.na(import_var)) %>%
mutate(new_variable = complicated_transformation(x, y, z))
```dependson deve contenere un vettore di caratteri di ogni chunk da cui il chunk in cache dipende. Knitr aggiornerà i risultati del chunk in cache ogni volta che rileverà che una delle sue dipendenze è cambiata.
Si noti che i chunk non verranno aggiornati se a_very_large_file.csv cambia, perché la cache di Knitr tiene traccia solo dei cambiamenti all’interno del file .Rmd. Se si vuole tenere traccia anche delle modifiche a quel file, si può usare l’opzione cache.extra. Si tratta di un’espressione R arbitraria che invalida la cache ogni volta che viene modificata. Una buona funzione da usare è file.info(): restituisce una serie di informazioni sul file, compresa l’ultima modifica. Quindi si può scrivere:
```{r raw_data, cache.extra = file.info("a_very_large_file.csv")}
rawdata <- readr::read_csv("a_very_large_file.csv")
```Quando le strategie di cache diventano progressivamente più complicate, è una buona idea svuotare regolarmente tutte le cache con knitr::clean_cache().
Ho usato il consiglio di David Robinson per dare un nome a questi chunk: ogni chunk ha il nome dell’oggetto primario che crea. Questo rende più facile la comprensione della specifica dependson.
27.4.5 Opzioni globali
Lavorando di più con knitr, si scoprirà che alcune delle opzioni predefinite dei chunk non sono adatte alle proprie esigenze e si vorrà cambiarle. È possibile farlo chiamando knitr::opts_chunk$set() in un pezzo di codice. Per esempio, quando scrivo libri e tutorial, imposto:
knitr::opts_chunk$set(
comment = "#>",
collapse = TRUE
)Questo utilizza la formattazione dei commenti che preferisco e garantisce che il codice e l’output siano strettamente legati. D’altra parte, se si stesse preparando una relazione, si potrebbe impostare:
knitr::opts_chunk$set(
echo = FALSE
)Questo nasconderà il codice per impostazione predefinita, mostrando solo le parti che si sceglie deliberatamente di mostrare (con echo = TRUE). Si potrebbe pensare di impostare message = FALSE e warning = FALSE, ma questo renderebbe più difficile il debug dei problemi, perché non si vedrebbe alcun messaggio nel documento finale.
27.4.6 Codice in linea
Esiste un altro modo per incorporare codice R in un documento R Markdown: direttamente nel testo, con: `r `. Questo può essere molto utile se si citano le proprietà dei dati nel testo. Per esempio, nel documento di esempio che ho usato all’inizio del capitolo, avevo:
Abbiamo dati sui diamanti di
`r nrow(diamonds)`. Solo`r nrow(diamonds) - nrow(smaller)`sono più grandi di di 2,5 carati. La distribuzione dei rimanenti è mostrata di seguito:
Quando il report viene lavorato a maglia, i risultati di questi calcoli vengono inseriti nel testo:
Abbiamo dati su 53940 diamanti. Solo 126 sono più grandi di 2,5 carati. La distribuzione dei rimanenti è mostrata di seguito:
Quando si inseriscono numeri nel testo, format() è un amico. Permette di impostare il numero di cifre', in modo da non stampare con una precisione ridicola, e unbig.mark’ per rendere i numeri più facili da leggere. Spesso le combino in una funzione di aiuto:
comma <- function(x) format(x, digits = 2, big.mark = ",")
comma(3452345)
#> [1] "3,452,345"
comma(.12358124331)
#> [1] "0.12"27.4.7 Esercizi
Aggiungere una sezione che esplori come le dimensioni dei diamanti variano in base al taglio, al colore e alla purezza, e chiarezza. Si supponga di scrivere una relazione per qualcuno che non conosce R. R, e invece di impostare
echo = FALSEsu ogni pezzo, impostate un’opzione globale. globale.Scaricare
diamond-sizes.Rmdda https://github.com/hadley/r4ds/tree/master/rmarkdown. Aggiungete una sezione che descriva i 20 diamanti più grandi, inclusa una tabella che mostri i loro gli attributi più importanti.Modificare
diamonds-sizes.Rmdper utilizzarecomma()per produrre un output ben formattato. Includere anche la percentuale di diamanti più grandi di 2,5 carati.Impostare una rete di pezzi dove
ddipende daceb, e siabchecdipendono daa. Fate in modo che ogni chunk stampilubridate::now(), impostarecache = TRUE, quindi verificare la comprensione della cache.
27.5 Risoluzione dei problemi
La risoluzione dei problemi dei documenti R Markdown può essere impegnativa, perché non ci si trova più in un ambiente R interattivo, e sarà necessario imparare alcuni nuovi trucchi. La prima cosa da fare è ricreare il problema in una sessione interattiva. Riavviate R, quindi “Esegui tutti i pezzi” (dal menu Codice, sotto la voce Esegui regione) o con la scorciatoia da tastiera Ctrl + Alt + R. Se siete fortunati, questo ricreerà il problema e potrete capire cosa sta succedendo in modo interattivo.
Se questo non aiuta, deve esserci qualcosa di diverso tra l’ambiente interattivo e l’ambiente markdown di R. È necessario sistemare l’ambiente interattivo e l’ambiente markdown. È necessario esplorare sistematicamente le opzioni. La differenza più comune è la directory di lavoro: la directory di lavoro di un markdown R è la directory in cui risiede. Verificate che la directory di lavoro sia quella che vi aspettate includendo getwd() in un chunk.
Successivamente, si deve fare un brainstorming di tutte le cose che potrebbero causare il bug. È necessario verificare sistematicamente che siano gli stessi nella sessione R e nella sessione R markdown. Il modo più semplice per farlo è impostare error = TRUE sul pezzo che causa il problema, quindi usare print() e str() per verificare che le impostazioni siano quelle previste.
27.6 Intestazione YAML
È possibile controllare molte altre impostazioni dell’intero documento modificando i parametri dell’intestazione YAML. Ci si potrebbe chiedere cosa significhi YAML: è “un altro linguaggio di markup”, progettato per rappresentare dati gerarchici in modo facile da leggere e scrivere per gli esseri umani. R Markdown lo usa per controllare molti dettagli dell’output. Qui ne discuteremo due: i parametri del documento e le bibliografie.
27.6.1 Parametri
I documenti R Markdown possono includere uno o più parametri i cui valori possono essere impostati durante il rendering del report. I parametri sono utili quando si vuole riproporre lo stesso report con valori diversi per vari input chiave. Ad esempio, si possono produrre rapporti di vendita per filiale, risultati di esami per studente o riepiloghi demografici per paese. Per dichiarare uno o più parametri, utilizzare il campo params.
Questo esempio utilizza il parametro my_class per determinare la classe di auto da visualizzare:
---
output: html_document
params:
my_class: "suv"
---
```{r setup, include = FALSE}
library(ggplot2)
library(dplyr)
class <- mpg %>% filter(class == params$my_class)
```
# Fuel economy for `r params$my_class`s
```{r, message = FALSE}
ggplot(class, aes(displ, hwy)) +
geom_point() +
geom_smooth(se = FALSE)
```Come si può vedere, i parametri sono disponibili all’interno dei pezzi di codice come un elenco di sola lettura chiamato params.
È possibile scrivere vettori atomici direttamente nell’intestazione YAML. È anche possibile eseguire espressioni R arbitrarie, anteponendo al valore del parametro !r. Questo è un buon modo per specificare parametri di data/ora.
params:
start: !r lubridate::ymd("2015-01-01")
snapshot: !r lubridate::ymd_hms("2015-01-01 12:30:00")In RStudio, è possibile fare clic sull’opzione “Knit with Parameters” nel menu a discesa Knit per impostare i parametri, eseguire il rendering e visualizzare l’anteprima del report in un unico passaggio di facile utilizzo. È possibile personalizzare la finestra di dialogo impostando altre opzioni nell’intestazione. Per ulteriori dettagli, vedere http://rmarkdown.rstudio.com/developer_parameterized_reports.html#parameter_user_interfaces.
In alternativa, se è necessario produrre molti rapporti parametrati, si può chiamare rmarkdown::render() con un elenco di parametri:
È particolarmente potente in combinazione con purrr:pwalk(). L’esempio seguente crea un report per ogni valore di classe trovato in mpg. Per prima cosa si crea un frame di dati con una riga per ogni classe, indicando il nome del file del report e i parametri:
reports <- tibble(
class = unique(mpg$class),
filename = stringr::str_c("fuel-economy-", class, ".html"),
params = purrr::map(class, ~ list(my_class = .))
)
reports
#> # A tibble: 7 × 3
#> class filename params
#> <chr> <chr> <list>
#> 1 compact fuel-economy-compact.html <named list [1]>
#> 2 midsize fuel-economy-midsize.html <named list [1]>
#> 3 suv fuel-economy-suv.html <named list [1]>
#> 4 2seater fuel-economy-2seater.html <named list [1]>
#> 5 minivan fuel-economy-minivan.html <named list [1]>
#> 6 pickup fuel-economy-pickup.html <named list [1]>
#> # … with 1 more rowQuindi si abbinano i nomi delle colonne ai nomi degli argomenti di render() e si usa il metodo parallel di Purrr per chiamare render() una volta per ogni riga:
27.6.2 Bibliografie e citazioni
Pandoc può generare automaticamente citazioni e una bibliografia in diversi stili. Per utilizzare questa funzione, specificare un file di bibliografia utilizzando il campo `bibliografia’ nell’intestazione del file. Il campo deve contenere un percorso dalla directory che contiene il file .Rmd al file che contiene la bibliografia:
bibliografia: rmarkdown.bibÈ possibile utilizzare molti formati di bibliografia comuni, tra cui BibLaTeX, BibTeX, endnote, medline.
Per creare una citazione all’interno del file .Rmd, utilizzare una chiave composta da ‘@’ + l’identificatore della citazione dal file di bibliografia. Quindi inserire la citazione tra parentesi quadre. Ecco alcuni esempi:
Separare più citazioni con un `;`: Blah blah [@smith04; @doe99].
È possibile aggiungere commenti arbitrari all'interno delle parentesi quadre:
Blah blah [cfr. @doe99, pp. 33-35; anche @smith04, cap. 1].
Rimuovere le parentesi quadre per creare una citazione nel testo: @smith04
dice bla, oppure @smith04 [p. 33] dice bla.
Aggiungere un `-` prima della citazione per sopprimere il nome dell'autore:
Smith dice bla [-@smith04].Quando R Markdown esegue il rendering del file, costruisce e aggiunge una bibliografia alla fine del documento. La bibliografia conterrà tutti i riferimenti citati nel file di bibliografia, ma non conterrà un titolo di sezione. Di conseguenza, è prassi comune terminare il file con un’intestazione di sezione per la bibliografia, come # Riferimenti o # Bibliografia.
È possibile modificare lo stile delle citazioni e della bibliografia facendo riferimento a un file CSL (citation style language) nel campo csl:
bibliografia: rmarkdown.bib
CSL: apa.cslCome per il campo bibliografia, il file csl deve contenere il percorso del file. Qui assumo che il file csl si trovi nella stessa directory del file .Rmd. Un buon posto dove trovare i file di stile CSL per gli stili di bibliografia più comuni è http://github.com/citation-style-language/styles.
27.7 Per saperne di più
R Markdown è ancora relativamente giovane e sta crescendo rapidamente. Il posto migliore per rimanere aggiornati sulle novità è il sito ufficiale di R Markdown: http://rmarkdown.rstudio.com.
Ci sono due argomenti importanti che non sono stati trattati qui: la collaborazione e i dettagli per comunicare accuratamente le proprie idee ad altri esseri umani. La collaborazione è una parte vitale della moderna scienza dei dati e potete semplificarvi la vita utilizzando strumenti di controllo delle versioni, come Git e GitHub. Vi consigliamo due risorse gratuite che vi insegneranno a conoscere Git:
“Happy Git with R”: un’introduzione semplice a Git e GitHub per gli utenti di R, a cura di Jenny Bryan. utenti di R, di Jenny Bryan. Il libro è disponibile gratuitamente online: http://happygitwithr.com
Il capitolo “Git e GitHub” di R Packages, di Hadley. È anche possibile leggerlo gratuitamente online: http://r-pkgs.had.co.nz/git.html.
Non ho nemmeno parlato di ciò che dovreste scrivere per comunicare chiaramente i risultati della vostra analisi. Per migliorare la vostra scrittura, vi consiglio di leggere [Style: Lessons in Clarity and Grace] (https://amzn.com/0134080416) di Joseph M. Williams e Joseph Bizup, oppure [The Sense of Structure: Writing from the Reader’s Perspective] (https://amzn.com/0205296327) di George Gopen. Entrambi i libri vi aiuteranno a capire la struttura delle frasi e dei paragrafi e vi daranno gli strumenti per rendere più chiara la vostra scrittura. (Questi libri sono piuttosto costosi se acquistati nuovi, ma sono utilizzati da molti corsi di inglese, quindi si trovano molte copie di seconda mano a buon mercato). George Gopen ha anche una serie di brevi articoli sulla scrittura all’indirizzo https://www.georgegopen.com/the-litigation-articles.html. Sono rivolti agli avvocati, ma quasi tutto si applica anche agli scienziati dei dati.