5 Trasformazione
5.1 Introduzione
La visualizzazione è uno strumento importante per la generare intuizioni, ma è raro che si ottengano i dati esattamente nella forma giusta di cui si ha bisogno. Spesso avrete bisogno di creare nuove variabili o sommari, o forse volete solo rinominare le variabili o riordinare le osservazioni per rendere i dati un po’ più facili da lavorare. Imparerete come fare tutto questo (e molto di più!) in questo capitolo, che vi insegnerà come trasformare i vostri dati usando il pacchetto dplyr e un nuovo set di dati sui voli in partenza da New York City nel 2013.
5.1.1 Prerequisiti
In questo capitolo ci concentreremo su come utilizzare il pacchetto dplyr, un altro membro fondamentale del tidyverse. Illustreremo le idee chiave usando i dati del pacchetto nycflights13 e useremo ggplot2 per aiutarci a capire i dati.
Fai attenzione al messaggio di conflitto che viene stampato quando carichi il tidyverse. Ti dice che dplyr sovrascrive alcune funzioni in R base. Se vuoi usare la versione base di queste funzioni dopo aver caricato dplyr, dovrai usare i loro nomi completi: stats::filter() e stats::lag().
5.1.2 nycflights13
Per esplorare i verbi di base di manipolazione dei dati di dplyr, useremo nycflights13::flights. Questo data frame contiene tutti i voli 336,776 che sono partiti da New York City nel 2013. I dati provengono dall’US Bureau of Transportation Statistics, ed è documentato in ?flights.
flights
#> # A tibble: 336,776 × 19
#> year month day dep_time sched_dep…¹ dep_d…² arr_t…³ sched…⁴ arr_d…⁵ carrier
#> <int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr>
#> 1 2013 1 1 517 515 2 830 819 11 UA
#> 2 2013 1 1 533 529 4 850 830 20 UA
#> 3 2013 1 1 542 540 2 923 850 33 AA
#> 4 2013 1 1 544 545 -1 1004 1022 -18 B6
#> 5 2013 1 1 554 600 -6 812 837 -25 DL
#> 6 2013 1 1 554 558 -4 740 728 12 UA
#> # … with 336,770 more rows, 9 more variables: flight <int>, tailnum <chr>,
#> # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
#> # minute <dbl>, time_hour <dttm>, and abbreviated variable names
#> # ¹sched_dep_time, ²dep_delay, ³arr_time, ⁴sched_arr_time, ⁵arr_delayPotreste notare che questo data frame viene visualizzato in console in modo un po’ diverso da altri data frame che potreste aver usato in passato: mostra solo le prime righe e tutte le colonne che stanno in uno schermo. (Per vedere l’intero dataset, potete eseguire View(flights) che aprirà il dataset nel visualizzatore di RStudio). Si ‘stampa’ (a video) in modo diverso perché è un tibble. I tibble sono data frame, ma leggermente modificati per funzionare meglio nel tidyverse. Per ora, non dovete preoccuparvi delle differenze; torneremo sui tibble in modo più dettagliato in wrangle.
Potreste anche aver notato la fila di abbreviazioni di tre (o quattro) lettere sotto i nomi delle colonne. Queste descrivono il tipo di ogni variabile:
intsta per gli interi.dblsta per i doppi, o numeri reali.chrsta per vettori di caratteri, o stringhe.dttmsta per data-ora (una data + un’ora).
Ci sono altri tre tipi comuni di variabili che non sono usati in questo set di dati ma che incontrerete più avanti nel libro:
lglsta per logico, vettori che contengono soloTRUEoFALSE.fctrsta per fattori, che R usa per rappresentare variabili categoriche con possibili valori fissi.datesta per le date.
5.1.3 Basi del dplyr
In questo capitolo imparerete le cinque funzioni chiave di dplyr che vi permettono di risolvere la maggior parte delle vostre sfide di manipolazione dei dati:
- Scegliere le osservazioni in base ai loro valori (
filter()). - Riordinare le righe (
arrange()). - Scegliere le variabili in base ai loro nomi (
select()). - Creare nuove variabili con funzioni di variabili esistenti (
mutate()). - Collassare molti valori in un singolo sommario (
summarise()).
Tutte queste funzioni possono essere usate insieme a group_by() che cambia lo scopo di ogni funzione dall’operare sull’intero set di dati all’operare su di esso gruppo per gruppo. Queste sei funzioni forniscono i verbi per un linguaggio di manipolazione dei dati.
Tutti i verbi funzionano in modo simile:
Il primo argomento è un data frame.
Gli argomenti successivi descrivono cosa fare con il data frame, usando i nomi delle variabili (senza virgolette).
Il risultato è un nuovo data frame.
Insieme queste proprietà rendono facile concatenare più passi semplici per ottenere un risultato complesso. Immergiamoci e vediamo come funzionano questi verbi.
5.2 Filtrare le righe con filter()
La funzione filter() permette di selezionare le osservazioni in base ai loro valori. Il primo argomento è il nome del data frame. Il secondo e i successivi argomenti sono le espressioni che filtrano il data frame. Per esempio, possiamo selezionare tutti i voli del 1° gennaio con:
filter(flights, month == 1, day == 1)
#> # A tibble: 842 × 19
#> year month day dep_time sched_dep…¹ dep_d…² arr_t…³ sched…⁴ arr_d…⁵ carrier
#> <int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr>
#> 1 2013 1 1 517 515 2 830 819 11 UA
#> 2 2013 1 1 533 529 4 850 830 20 UA
#> 3 2013 1 1 542 540 2 923 850 33 AA
#> 4 2013 1 1 544 545 -1 1004 1022 -18 B6
#> 5 2013 1 1 554 600 -6 812 837 -25 DL
#> 6 2013 1 1 554 558 -4 740 728 12 UA
#> # … with 836 more rows, 9 more variables: flight <int>, tailnum <chr>,
#> # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
#> # minute <dbl>, time_hour <dttm>, and abbreviated variable names
#> # ¹sched_dep_time, ²dep_delay, ³arr_time, ⁴sched_arr_time, ⁵arr_delayQuando esegui quella linea di codice, dplyr esegue l’operazione di filtraggio e restituisce un nuovo data frame. Le funzioni dplyr non modificano mai i loro input, quindi se vuoi salvare il risultato, dovrai usare l’operatore di assegnazione, <-:
jan1 <- filter(flights, month == 1, day == 1)R stampa i risultati o li salva in una variabile. Se volete fare entrambe le cose, potete avvolgere l’assegnazione tra parentesi:
(dec25 <- filter(flights, month == 12, day == 25))
#> # A tibble: 719 × 19
#> year month day dep_time sched_dep…¹ dep_d…² arr_t…³ sched…⁴ arr_d…⁵ carrier
#> <int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr>
#> 1 2013 12 25 456 500 -4 649 651 -2 US
#> 2 2013 12 25 524 515 9 805 814 -9 UA
#> 3 2013 12 25 542 540 2 832 850 -18 AA
#> 4 2013 12 25 546 550 -4 1022 1027 -5 B6
#> 5 2013 12 25 556 600 -4 730 745 -15 AA
#> 6 2013 12 25 557 600 -3 743 752 -9 DL
#> # … with 713 more rows, 9 more variables: flight <int>, tailnum <chr>,
#> # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
#> # minute <dbl>, time_hour <dttm>, and abbreviated variable names
#> # ¹sched_dep_time, ²dep_delay, ³arr_time, ⁴sched_arr_time, ⁵arr_delay5.2.1 Confronti
Per usare efficacemente il filtraggio, dovete sapere come selezionare le osservazioni che volete usando gli operatori di confronto. R fornisce la serie standard: >, >=, <, <=, != (non uguale), e == (uguale).
Quando sei agli inizi con R, l’errore più facile da fare è usare = invece di == quando si verifica l’uguaglianza. Quando questo accade otterrete un errore informativo:
filter(flights, month = 1)
#> Error in `filter()`:
#> ! We detected a named input.
#> ℹ This usually means that you've used `=` instead of `==`.
#> ℹ Did you mean `month == 1`?C’è un altro problema comune che potresti incontrare quando usi ==: i numeri in virgola mobile. Questi risultati potrebbero sorprenderti!
sqrt(2) ^ 2 == 2
#> [1] FALSE
1 / 49 * 49 == 1
#> [1] FALSEI computer usano l’aritmetica a precisione finita (ovviamente non possono memorizzare un numero infinito di cifre!) quindi ricordate che ogni numero che vedete è un’approssimazione. Invece di fare affidamento su ==, usa near():
5.2.2 Operatori logici
Gli argomenti multipli di filter() sono combinati con “and”: ogni espressione deve essere vera perché una riga sia inclusa nell’output. Per altri tipi di combinazioni, dovrai usare tu stesso gli operatori booleani: & è “and”, | è “or”, e ! è “not”. La figura 5.1 mostra l’insieme completo delle operazioni booleane.
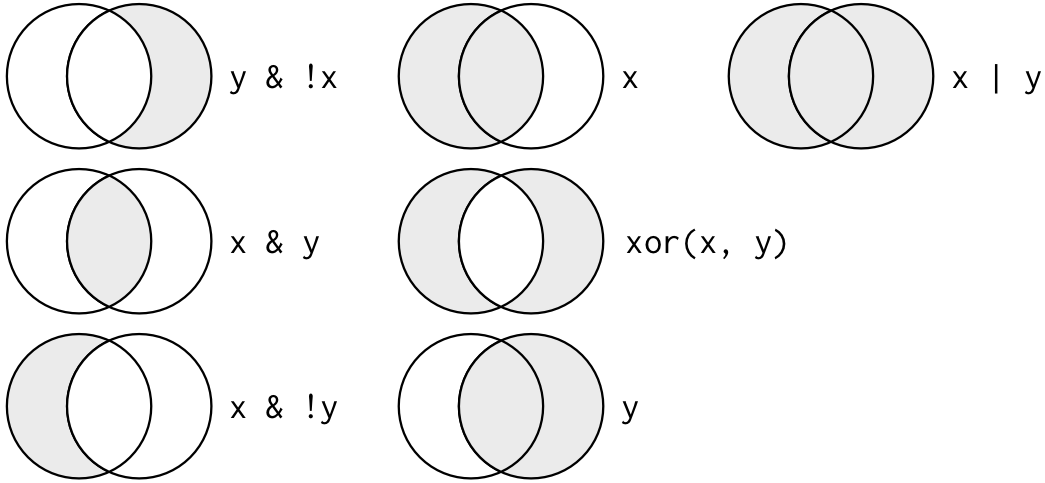
Figure 5.1: Set completo di operazioni booleane. x è il cerchio di sinistra, y è il cerchio di destra, e la regione ombreggiata mostra quali parti ogni operatore seleziona.
Il seguente codice trova tutti i voli che sono partiti in novembre o dicembre:
filter(flights, month == 11 | month == 12)L’ordine delle operazioni non funziona come l’italiano. Non potete scrivere filter(flights, month == (11 | 12)), che potreste tradurre letteralmente in “trova tutti i voli che sono partiti in novembre o dicembre”. Invece trova tutti i mesi che sono uguali a 11 | 12, un’espressione che valuta TRUE. In un contesto numerico (come qui), TRUE diventa uno, quindi questo comando trova tutti i voli in gennaio, non in novembre o dicembre. Il tutto è abbastanza confondente!
Un’utile abbreviazione per questo problema è x %in% y. Questo selezionerà ogni riga dove x è uno dei valori in y. Potremmo usarla per riscrivere il codice sopra:
A volte puoi semplificare i sottoinsiemi complicati ricordando la legge di De Morgan: !(x & y) è uguale a !x | !y, e !(x | y) è uguale a !x & !y. Per esempio, se vuoi trovare i voli che non sono stati in ritardo (all’arrivo o alla partenza) di più di due ore, puoi usare uno dei due filtri seguenti:
filter(flights, !(arr_delay > 120 | dep_delay > 120))
filter(flights, arr_delay <= 120, dep_delay <= 120)Oltre a & e |, R ha anche && e ||. Non usateli qui! Imparerete quando dovreste usarli in esecuzione condizionale.
Ogni volta che iniziate ad usare espressioni complicate e composte da più parti in filter(), considerate invece di renderle variabili esplicite. Questo rende molto più facile controllare il vostro lavoro. Imparerai a breve come creare nuove variabili.
5.2.3 Valori mancanti
Una caratteristica importante di R che può rendere difficile il confronto sono i valori mancanti, o NAs (“not availables”). NA rappresenta un valore sconosciuto quindi i valori mancanti sono “contagiosi”: quasi ogni operazione che coinvolge un valore sconosciuto sarà anch’essa sconosciuta.
NA > 5
#> [1] NA
10 == NA
#> [1] NA
NA + 10
#> [1] NA
NA / 2
#> [1] NAIl risultato più disorientante è questo:
NA == NA
#> [1] NAÈ più facile capire perché questo è vero con un po’ più di contesto:
# Sia x l'età di Mary. Non sappiamo quanti anni ha.
x <- NA
# Sia y l'età di John. Non sappiamo quanti anni ha.
y <- NA
# John e Mary hanno la stessa età?
x == y
#> [1] NA
# Non lo sappiamo!Se volete determinare se un valore è mancante, usate is.na():
is.na(x)
#> [1] TRUEfilter() include solo le righe in cui la condizione è TRUE; esclude sia i valori FALSE che NA. Se vuoi conservare i valori mancanti, chiedili esplicitamente:
5.2.4 Esercizi
-
Trovi tutti i voli che
- Hanno avuto un ritardo all’arrivo di due o più ore
- Hanno volato a Houston (
IAHoHOU) - Sono stati operati da United, American o Delta
- Sono partiti in estate (luglio, agosto e settembre)
- Sono arrivati con più di due ore di ritardo, ma non sono partiti in ritardo
- Hanno subito un ritardo di almeno un’ora, ma hanno recuperato più di 30 minuti di volo
- Sono partiti tra mezzanotte e le 6 del mattino (compreso)
Un altro utile helper di filtraggio di dplyr è
between(). Cosa fa? Puoi usarlo per semplificare il codice necessario per rispondere alle sfide precedenti?Quanti voli hanno un
dep_timemancante? Quali altre variabili sono mancanti? Cosa potrebbero rappresentare queste righe?-
Perché la variabile
NA ^ 0non è mancante? 2. PerchéNA | TRUEnon è mancante?- Perché
FALSE & NAnon è mancante? Puoi capire la regola generale? (NA * 0è un controesempio insidioso!)
- Perché
5.3 Organizzare le righe con arrange()
Arrange()funziona in modo simile afilter()` tranne che invece di selezionare le righe, cambia il loro ordine. Prende un frame di dati e un insieme di nomi di colonne (o espressioni più complicate) da ordinare. Se fornite più di un nome di colonna, ogni colonna aggiuntiva sarà usata per rompere i legami nei valori delle colonne precedenti:
arrange(flights, year, month, day)
#> # A tibble: 336,776 × 19
#> year month day dep_time sched_dep…¹ dep_d…² arr_t…³ sched…⁴ arr_d…⁵ carrier
#> <int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr>
#> 1 2013 1 1 517 515 2 830 819 11 UA
#> 2 2013 1 1 533 529 4 850 830 20 UA
#> 3 2013 1 1 542 540 2 923 850 33 AA
#> 4 2013 1 1 544 545 -1 1004 1022 -18 B6
#> 5 2013 1 1 554 600 -6 812 837 -25 DL
#> 6 2013 1 1 554 558 -4 740 728 12 UA
#> # … with 336,770 more rows, 9 more variables: flight <int>, tailnum <chr>,
#> # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
#> # minute <dbl>, time_hour <dttm>, and abbreviated variable names
#> # ¹sched_dep_time, ²dep_delay, ³arr_time, ⁴sched_arr_time, ⁵arr_delayUsa desc() per riordinare una colonna in ordine decrescente:
arrange(flights, desc(dep_delay))
#> # A tibble: 336,776 × 19
#> year month day dep_time sched_dep…¹ dep_d…² arr_t…³ sched…⁴ arr_d…⁵ carrier
#> <int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr>
#> 1 2013 1 9 641 900 1301 1242 1530 1272 HA
#> 2 2013 6 15 1432 1935 1137 1607 2120 1127 MQ
#> 3 2013 1 10 1121 1635 1126 1239 1810 1109 MQ
#> 4 2013 9 20 1139 1845 1014 1457 2210 1007 AA
#> 5 2013 7 22 845 1600 1005 1044 1815 989 MQ
#> 6 2013 4 10 1100 1900 960 1342 2211 931 DL
#> # … with 336,770 more rows, 9 more variables: flight <int>, tailnum <chr>,
#> # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
#> # minute <dbl>, time_hour <dttm>, and abbreviated variable names
#> # ¹sched_dep_time, ²dep_delay, ³arr_time, ⁴sched_arr_time, ⁵arr_delayI valori mancanti sono sempre ordinati alla fine:
df <- tibble(x = c(5, 2, NA))
arrange(df, x)
#> # A tibble: 3 × 1
#> x
#> <dbl>
#> 1 2
#> 2 5
#> 3 NA
arrange(df, desc(x))
#> # A tibble: 3 × 1
#> x
#> <dbl>
#> 1 5
#> 2 2
#> 3 NA5.3.1 Esercizi
Come potreste usare
arrange()per ordinare tutti i valori mancanti all’inizio? (Suggerimento: usateis.na()).Ordina
flightsper trovare i voli più in ritardo. Trova i voli che sono partiti prima.Ordina i voli per trovare i voli più veloci.
Quali voli hanno viaggiato più lontano? Quali hanno viaggiato più brevemente?
5.4 Seleziona le colonne con select()
Non è raro avere serie di dati con centinaia o addirittura migliaia di variabili. In questo caso, la prima sfida è spesso quella di restringere le variabili a cui si è effettivamente interessati. La funzione select() permette di zoomare rapidamente su un sottoinsieme utile usando operazioni basate sui nomi delle variabili.
La funzione select() non è estremamente utile con i dati dei voli perché abbiamo solo 19 variabili, ma potete comunque farvi un’idea generale:
# Seleziona le colonne per nome
select(flights, year, month, day)
#> # A tibble: 336,776 × 3
#> year month day
#> <int> <int> <int>
#> 1 2013 1 1
#> 2 2013 1 1
#> 3 2013 1 1
#> 4 2013 1 1
#> 5 2013 1 1
#> 6 2013 1 1
#> # … with 336,770 more rows
# Seleziona tutte le colonne tra l'anno e il giorno (incluso)
select(flights, year:day)
#> # A tibble: 336,776 × 3
#> year month day
#> <int> <int> <int>
#> 1 2013 1 1
#> 2 2013 1 1
#> 3 2013 1 1
#> 4 2013 1 1
#> 5 2013 1 1
#> 6 2013 1 1
#> # … with 336,770 more rows
# Seleziona tutte le colonne tranne quelle dall'anno al giorno (incluso)
select(flights, -(year:day))
#> # A tibble: 336,776 × 16
#> dep_time sched…¹ dep_d…² arr_t…³ sched…⁴ arr_d…⁵ carrier flight tailnum origin
#> <int> <int> <dbl> <int> <int> <dbl> <chr> <int> <chr> <chr>
#> 1 517 515 2 830 819 11 UA 1545 N14228 EWR
#> 2 533 529 4 850 830 20 UA 1714 N24211 LGA
#> 3 542 540 2 923 850 33 AA 1141 N619AA JFK
#> 4 544 545 -1 1004 1022 -18 B6 725 N804JB JFK
#> 5 554 600 -6 812 837 -25 DL 461 N668DN LGA
#> 6 554 558 -4 740 728 12 UA 1696 N39463 EWR
#> # … with 336,770 more rows, 6 more variables: dest <chr>, air_time <dbl>,
#> # distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>, and abbreviated
#> # variable names ¹sched_dep_time, ²dep_delay, ³arr_time, ⁴sched_arr_time,
#> # ⁵arr_delayCi sono un certo numero di funzioni di aiuto che potete usare all’interno di select():
starts_with("abc"): corrisponde ai nomi che iniziano con “abc”.ends_with("xyz"): corrisponde ai nomi che finiscono con “xyz”.contains("ijk"): corrisponde ai nomi che contengono “ijk”.matches("(.)\1"): seleziona le variabili che corrispondono a un’espressione regolare. Questo corrisponde a tutte le variabili che contengono caratteri ripetuti. Imparerete imparerete di più sulle espressioni regolari in stringhe.num_range("x", 1:3): corrisponde ax1,x2ex3.
Vedi ?select per maggiori dettagli.
select() può essere usato per rinominare le variabili, ma è raramente utile perché elimina tutte le variabili non esplicitamente menzionate. Usate invece rename(), che è una variante di select() che mantiene tutte le variabili che non sono esplicitamente menzionate:
rename(flights, tail_num = tailnum)
#> # A tibble: 336,776 × 19
#> year month day dep_time sched_dep…¹ dep_d…² arr_t…³ sched…⁴ arr_d…⁵ carrier
#> <int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr>
#> 1 2013 1 1 517 515 2 830 819 11 UA
#> 2 2013 1 1 533 529 4 850 830 20 UA
#> 3 2013 1 1 542 540 2 923 850 33 AA
#> 4 2013 1 1 544 545 -1 1004 1022 -18 B6
#> 5 2013 1 1 554 600 -6 812 837 -25 DL
#> 6 2013 1 1 554 558 -4 740 728 12 UA
#> # … with 336,770 more rows, 9 more variables: flight <int>, tail_num <chr>,
#> # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
#> # minute <dbl>, time_hour <dttm>, and abbreviated variable names
#> # ¹sched_dep_time, ²dep_delay, ³arr_time, ⁴sched_arr_time, ⁵arr_delayUn’altra opzione è quella di usare select() insieme all’helper everything(). Questo è utile se hai una manciata di variabili che vorresti spostare all’inizio del data frame.
select(flights, time_hour, air_time, everything())
#> # A tibble: 336,776 × 19
#> time_hour air_time year month day dep_t…¹ sched…² dep_d…³ arr_t…⁴
#> <dttm> <dbl> <int> <int> <int> <int> <int> <dbl> <int>
#> 1 2013-01-01 05:00:00 227 2013 1 1 517 515 2 830
#> 2 2013-01-01 05:00:00 227 2013 1 1 533 529 4 850
#> 3 2013-01-01 05:00:00 160 2013 1 1 542 540 2 923
#> 4 2013-01-01 05:00:00 183 2013 1 1 544 545 -1 1004
#> 5 2013-01-01 06:00:00 116 2013 1 1 554 600 -6 812
#> 6 2013-01-01 05:00:00 150 2013 1 1 554 558 -4 740
#> # … with 336,770 more rows, 10 more variables: sched_arr_time <int>,
#> # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>, origin <chr>,
#> # dest <chr>, distance <dbl>, hour <dbl>, minute <dbl>, and abbreviated
#> # variable names ¹dep_time, ²sched_dep_time, ³dep_delay, ⁴arr_time5.4.1 Esercizi
Cerca il maggior numero possibile di modi per selezionare
dep_time,dep_delay,arr_timeearr_delaydaflights.Cosa succede se includi il nome di una variabile più volte in una chiamata
select()?-
Cosa fa la funzione
any_of()? Perché potrebbe essere utile in congiunzione con questo vettore?vars <- c("year", "month", "day", "dep_delay", "arr_delay") -
Il risultato dell’esecuzione del seguente codice vi sorprende? Come trattano le maiuscole le funzioni di aiuto di select in modo predefinito? Come si può cambiare questo default?
5.5 Aggiungere nuove variabili con mutate()
Oltre a selezionare insiemi di colonne esistenti, è spesso utile aggiungere nuove colonne che sono funzioni di colonne esistenti. Questo è il compito di mutate().
La funzione mutate() aggiunge sempre nuove colonne alla fine del vostro dataset, quindi inizieremo creando un dataset più piccolo in modo da poter vedere le nuove variabili. Ricordate che quando siete in RStudio, il modo più semplice per vedere tutte le colonne è View().
flights_sml <- select(flights,
year:day,
ends_with("delay"),
distance,
air_time
)
mutate(flights_sml,
gain = dep_delay - arr_delay,
speed = distance / air_time * 60
)
#> # A tibble: 336,776 × 9
#> year month day dep_delay arr_delay distance air_time gain speed
#> <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 2013 1 1 2 11 1400 227 -9 370.
#> 2 2013 1 1 4 20 1416 227 -16 374.
#> 3 2013 1 1 2 33 1089 160 -31 408.
#> 4 2013 1 1 -1 -18 1576 183 17 517.
#> 5 2013 1 1 -6 -25 762 116 19 394.
#> 6 2013 1 1 -4 12 719 150 -16 288.
#> # … with 336,770 more rowsNota che puoi fare riferimento alle colonne che hai appena creato:
mutate(flights_sml,
gain = dep_delay - arr_delay,
hours = air_time / 60,
gain_per_hour = gain / hours
)
#> # A tibble: 336,776 × 10
#> year month day dep_delay arr_delay distance air_time gain hours gain_per…¹
#> <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 2013 1 1 2 11 1400 227 -9 3.78 -2.38
#> 2 2013 1 1 4 20 1416 227 -16 3.78 -4.23
#> 3 2013 1 1 2 33 1089 160 -31 2.67 -11.6
#> 4 2013 1 1 -1 -18 1576 183 17 3.05 5.57
#> 5 2013 1 1 -6 -25 762 116 19 1.93 9.83
#> 6 2013 1 1 -4 12 719 150 -16 2.5 -6.4
#> # … with 336,770 more rows, and abbreviated variable name ¹gain_per_hourSe volete mantenere solo le nuove variabili, usate transmute():
transmute(flights,
gain = dep_delay - arr_delay,
hours = air_time / 60,
gain_per_hour = gain / hours
)
#> # A tibble: 336,776 × 3
#> gain hours gain_per_hour
#> <dbl> <dbl> <dbl>
#> 1 -9 3.78 -2.38
#> 2 -16 3.78 -4.23
#> 3 -31 2.67 -11.6
#> 4 17 3.05 5.57
#> 5 19 1.93 9.83
#> 6 -16 2.5 -6.4
#> # … with 336,770 more rows5.5.1 Funzioni utili per creare variabili
Ci sono molte funzioni per creare nuove variabili che potete usare con mutate(). La proprietà chiave è che la funzione deve essere vettorializzata: deve prendere un vettore di valori come input, restituire un vettore con lo stesso numero di valori come output. Non c’è modo di elencare tutte le possibili funzioni che potreste usare, ma ecco una selezione di funzioni che sono spesso utili:
-
Operatori aritmetici:
+,-,*,/,^. Questi sono tutti vettorializzati, usando le cosiddette “regole di riciclaggio”. Se un parametro è più corto dell’altro, sarà automaticamente esteso per avere la stessa lunghezza. E’ molto utile quando uno degli argomenti è un singolo numero:air_time / 60,ore * 60 + minuti, ecc.Gli operatori aritmetici sono utili anche in combinazione con le funzioni che imparerete in seguito. Per esempio,
x / sum(x)calcola la proporzione di un totale, ey - mean(y)calcola la differenza dalla la media. -
Aritmetica modulare:
%/%(divisione intera) e%%(resto), dovex == y * (x %/% y) + (x %% y). L’aritmetica modulare è uno strumento utile perché ti permette di spezzare gli interi in pezzi. Per esempio, nel set di dati voli, puoi calcolareoraeminutodadep_timecon: -
Logaritmi:
log(),log2(),log10(). I logaritmi sono una trasformazione incredibilmente utile per trattare con dati che spaziano su più ordini di grandezza. Essi convertono anche relazioni moltiplicative in additive, una caratteristica su cui torneremo nella modellazione.A parità di condizioni, raccomando di usare
log2()perché è facile da interpretare: una differenza di 1 sulla scala log corrisponde al raddoppio sulla scala originale e una differenza di -1 corrisponde al dimezzamento. -
Offset:
lead()elag()vi permettono di fare riferimento a valori in testa o in coda valori. Questo vi permette di calcolare le differenze correnti (ad esempio,x - lag(x)) o trovare quando i valori cambiano (x != lag(x)). Sono molto utili in insieme agroup_by(), che imparerete a conoscere tra poco. -
Aggregati cumulativi e rotativi: R fornisce funzioni per eseguire somme, prodotti, minimi e massimi:
cumsum(),cumprod(),cummin(),cummax(); e dplyr forniscecummean()per le medie cumulative. Se avete bisogno di aggregati rotativi (cioè una somma calcolata su una finestra mobile), provate il pacchetto RcppRoll. Confronti logici:
<,<=,>,>=,!=, e==, che hai imparato prima. Se stai facendo una complessa sequenza di operazioni logiche è spesso una buona idea memorizzare i valori intermedi in nuove variabili in modo da poter controllare che ogni passo funzioni come previsto.-
Rango: ci sono un certo numero di funzioni per i ranghi, ma si dovrebbe iniziare con
min_rank(). Esegue il tipo più usuale di classifica (es. 1°, 2°, 2°, 4°). Il default dà ai valori più piccoli il più piccolo dei ranghi; usatedesc(x)per dare ai valori più grandi i ranghi più piccoli.Se
min_rank()non fa ciò di cui avete bisogno, guardate le variantirow_number(),dense_rank(),percent_rank(),cume_dist(),ntile(). Vedi le loro pagine di aiuto per maggiori dettagli.row_number(y) #> [1] 1 2 3 NA 4 5 dense_rank(y) #> [1] 1 2 2 NA 3 4 percent_rank(y) #> [1] 0.00 0.25 0.25 NA 0.75 1.00 cume_dist(y) #> [1] 0.2 0.6 0.6 NA 0.8 1.0
5.5.2 Esercizi
Attualmente
dep_timeesched_dep_timesono comodi da guardare, ma difficili da calcolare perché non sono realmente numeri continui. Convertirli in una rappresentazione più conveniente del numero di minuti dalla mezzanotte.Confronta
air_timeconarr_time - dep_time. Cosa ti aspetti di vedere? Cosa vedi? Cosa devi fare per risolvere il problema?Confronta
dep_time,sched_dep_timeedep_delay. Come ti aspetteresti aspettarti che questi tre numeri siano correlati?Trova i 10 voli più in ritardo usando una funzione di classifica. Come vuoi gestire i pareggi? Leggete attentamente la documentazione per
min_rank().Cosa restituisce
1:3 + 1:10? Perché?Quali funzioni trigonometriche fornisce R?
5.6 Riassunti raggruppati con summarise()
L’ultimo verbo chiave è summarise(). Esso collassa un frame di dati in una singola riga:
summarise(flights, delay = mean(dep_delay, na.rm = TRUE))
#> # A tibble: 1 × 1
#> delay
#> <dbl>
#> 1 12.6(Torneremo a breve sul significato di quel na.rm = TRUE).
La funzione summarise() non è estremamente utile a meno che non la accoppiamo con la funzione group_by(). Questo cambia l’unità di analisi dall’intero set di dati ai singoli gruppi. Quindi, quando usate i verbi di dplyr su un data frame raggruppato, essi saranno automaticamente applicati “per gruppo”. Per esempio, se applicassimo esattamente lo stesso codice a un data frame raggruppato per data, otterremmo il ritardo medio per data:
by_day <- group_by(flights, year, month, day)
summarise(by_day, delay = mean(dep_delay, na.rm = TRUE))
#> `summarise()` has grouped output by 'year', 'month'. You can override using the
#> `.groups` argument.
#> # A tibble: 365 × 4
#> # Groups: year, month [12]
#> year month day delay
#> <int> <int> <int> <dbl>
#> 1 2013 1 1 11.5
#> 2 2013 1 2 13.9
#> 3 2013 1 3 11.0
#> 4 2013 1 4 8.95
#> 5 2013 1 5 5.73
#> 6 2013 1 6 7.15
#> # … with 359 more rowsInsieme group_by() e summarise() forniscono uno degli strumenti che userete più comunemente quando lavorate con dplyr: i sommari raggruppati. Ma prima di andare avanti con questo, dobbiamo introdurre una nuova potente idea: la pipe.
5.6.1 Combinare più operazioni con la ‘pipe’
Immaginate di voler esplorare la relazione tra la distanza e il ritardo medio per ogni località. Usando quello che sapete su dplyr, potreste scrivere del codice come questo:
by_dest <- group_by(flights, dest)
delay <- summarise(by_dest,
count = n(),
dist = mean(distance, na.rm = TRUE),
delay = mean(arr_delay, na.rm = TRUE)
)
delay <- filter(delay, count > 20, dest != "HNL")
# Sembra che i ritardi aumentino con la distanza fino a ~750 miglia
# e poi diminuiscono. Forse quando i voli diventano più lunghi c'è più
# capacità di recuperare i ritardi in volo?
ggplot(data = delay, mapping = aes(x = dist, y = delay)) +
geom_point(aes(size = count), alpha = 1/3) +
geom_smooth(se = FALSE)
#> `geom_smooth()` using method = 'loess' and formula = 'y ~ x'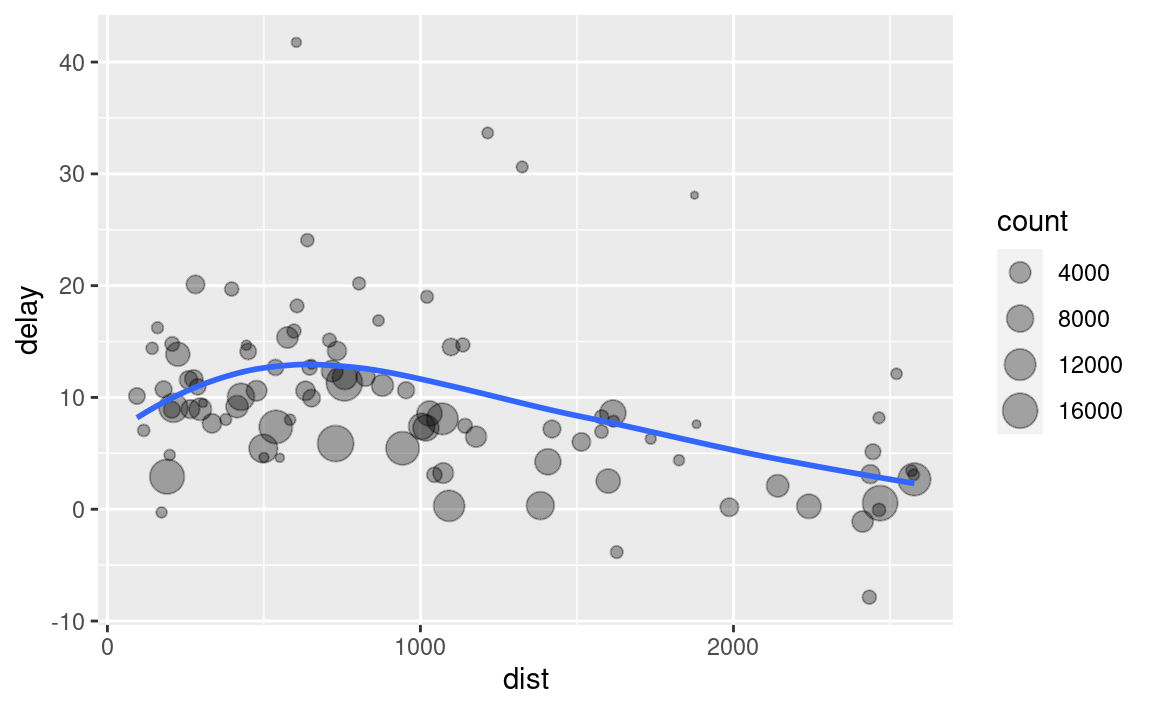
Ci sono tre passi per preparare questi dati:
Raggruppare i voli per destinazione.
Riassumere per calcolare la distanza, il ritardo medio e il numero di voli.
Filtrare per rimuovere i punti ‘rumorosi’ e l’aeroporto di Honolulu, che è quasi due volte più lontano del prossimo aeroporto più vicino.
Questo codice è un po’ frustrante da scrivere perché dobbiamo dare un nome ad ogni data frame intermedio, anche se non ci interessa. Dare un nome alle cose è difficile, quindi questo rallenta la nostra analisi.
C’è un altro modo per affrontare lo stesso problema con la pipe (‘condotta’ o ‘tubatura’), %>%:
delays <- flights %>%
group_by(dest) %>%
summarise(
count = n(),
dist = mean(distance, na.rm = TRUE),
delay = mean(arr_delay, na.rm = TRUE)
) %>%
filter(count > 20, dest != "HNL")Questo si concentra sulle trasformazioni, non su ciò che viene trasformato, il che rende il codice più facile da leggere. Potete leggerlo come una serie di dichiarazioni imperative: raggruppare, poi riassumere, poi filtrare. Come suggerito da questa lettura, un buon modo di pronunciare %>% quando si legge il codice è “poi”.
Dietro le quinte, x %>% f(y) si trasforma in f(x, y), e x %>% f(y) %>% g(z) si trasforma in g(f(x, y), z) e così via. Puoi usare la pipe per riscrivere operazioni multiple in modo da poterle leggere da sinistra a destra, dall’alto in basso. Useremo spesso la pipe d’ora in poi perché migliora considerevolmente la leggibilità del codice, e torneremo su di esso in modo più dettagliato in pipe.
Lavorare con la pipe è uno dei criteri chiave per appartenere al tidyverse. L’unica eccezione è ggplot2: è stato scritto prima che la pipe fosse scoperta. Sfortunatamente, la prossima iterazione di ggplot2, ggvis, che usa la pipe, non è ancora pronta per il prime time.
5.6.2 Valori mancanti
Vi sarete chiesti quale sia l’argomento na.rm che abbiamo usato sopra. Cosa succede se non lo impostiamo?
flights %>%
group_by(year, month, day) %>%
summarise(mean = mean(dep_delay))
#> `summarise()` has grouped output by 'year', 'month'. You can override using the
#> `.groups` argument.
#> # A tibble: 365 × 4
#> # Groups: year, month [12]
#> year month day mean
#> <int> <int> <int> <dbl>
#> 1 2013 1 1 NA
#> 2 2013 1 2 NA
#> 3 2013 1 3 NA
#> 4 2013 1 4 NA
#> 5 2013 1 5 NA
#> 6 2013 1 6 NA
#> # … with 359 more rowsAbbiamo un sacco di valori mancanti! Questo perché le funzioni di aggregazione obbediscono alla solita regola dei valori mancanti: se c’è un qualsiasi valore mancante nell’input, l’output sarà un valore mancante. Fortunatamente, tutte le funzioni di aggregazione hanno un argomento na.rm che rimuove i valori mancanti prima del calcolo:
flights %>%
group_by(year, month, day) %>%
summarise(mean = mean(dep_delay, na.rm = TRUE))
#> `summarise()` has grouped output by 'year', 'month'. You can override using the
#> `.groups` argument.
#> # A tibble: 365 × 4
#> # Groups: year, month [12]
#> year month day mean
#> <int> <int> <int> <dbl>
#> 1 2013 1 1 11.5
#> 2 2013 1 2 13.9
#> 3 2013 1 3 11.0
#> 4 2013 1 4 8.95
#> 5 2013 1 5 5.73
#> 6 2013 1 6 7.15
#> # … with 359 more rowsIn questo caso, dove i valori mancanti rappresentano voli cancellati, potremmo anche affrontare il problema rimuovendo prima i voli cancellati. Salveremo questo set di dati in modo da poterlo riutilizzare nei prossimi esempi.
not_cancelled <- flights %>%
filter(!is.na(dep_delay), !is.na(arr_delay))
not_cancelled %>%
group_by(year, month, day) %>%
summarise(mean = mean(dep_delay))
#> `summarise()` has grouped output by 'year', 'month'. You can override using the
#> `.groups` argument.
#> # A tibble: 365 × 4
#> # Groups: year, month [12]
#> year month day mean
#> <int> <int> <int> <dbl>
#> 1 2013 1 1 11.4
#> 2 2013 1 2 13.7
#> 3 2013 1 3 10.9
#> 4 2013 1 4 8.97
#> 5 2013 1 5 5.73
#> 6 2013 1 6 7.15
#> # … with 359 more rows5.6.3 Dati di conteggio
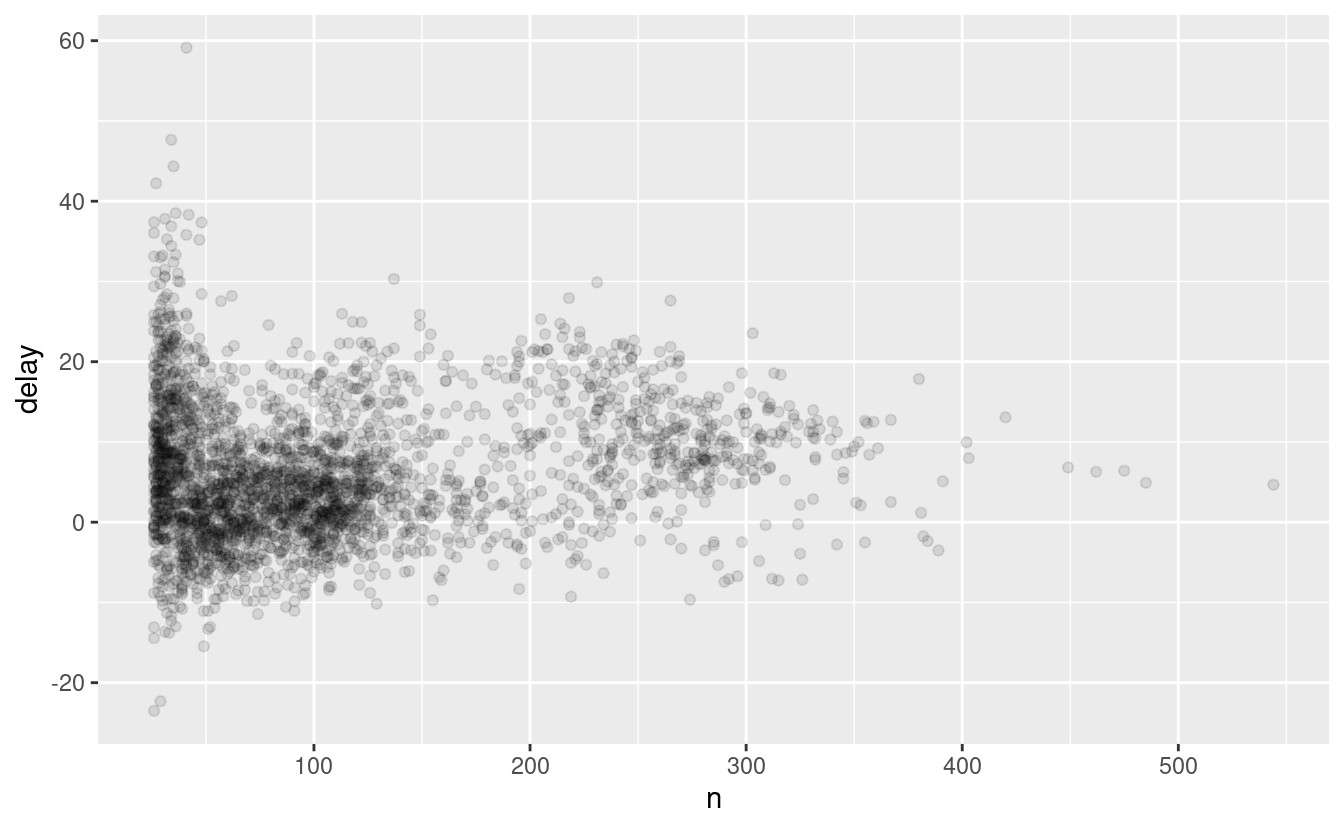
Ogni volta che fate un’aggregazione, è sempre una buona idea includere o un conteggio (n()), o un conteggio dei valori non mancanti (sum(!is.na(x))). In questo modo potete controllare che non stiate traendo conclusioni basate su quantità molto piccole di dati. Per esempio, guardiamo gli aerei (identificati dal loro numero di coda) che hanno i ritardi medi più alti:
delays <- not_cancelled %>%
group_by(tailnum) %>%
summarise(
delay = mean(arr_delay)
)
ggplot(data = delays, mapping = aes(x = delay)) +
geom_freqpoly(binwidth = 10)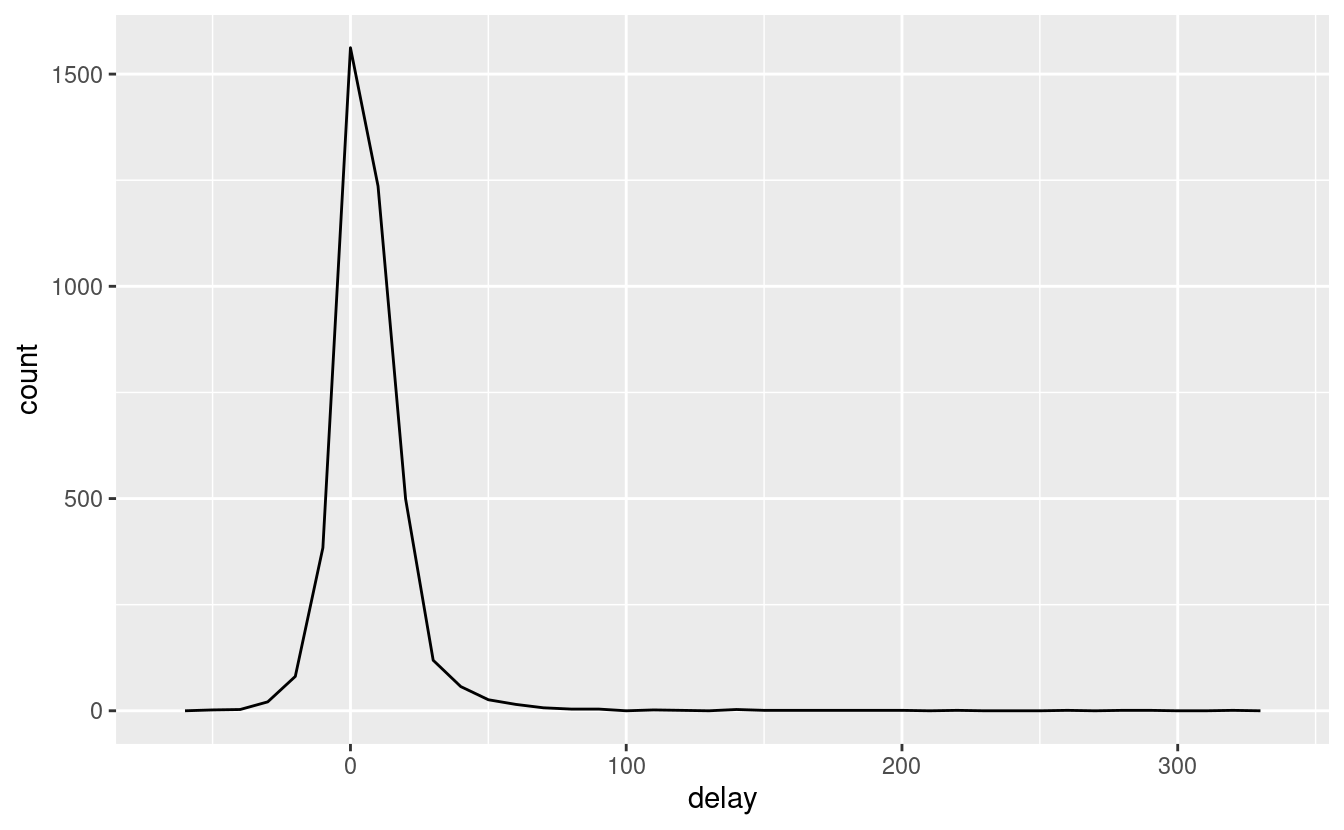
Wow, ci sono alcuni aerei che hanno un ritardo medio di 5 ore (300 minuti)!
La storia è in realtà un po’ più sfumata. Possiamo ottenere maggiori informazioni se disegniamo un grafico a dispersione del numero di voli rispetto al ritardo medio:
delays <- not_cancelled %>%
group_by(tailnum) %>%
summarise(
delay = mean(arr_delay, na.rm = TRUE),
n = n()
)
ggplot(data = delays, mapping = aes(x = n, y = delay)) +
geom_point(alpha = 1/10)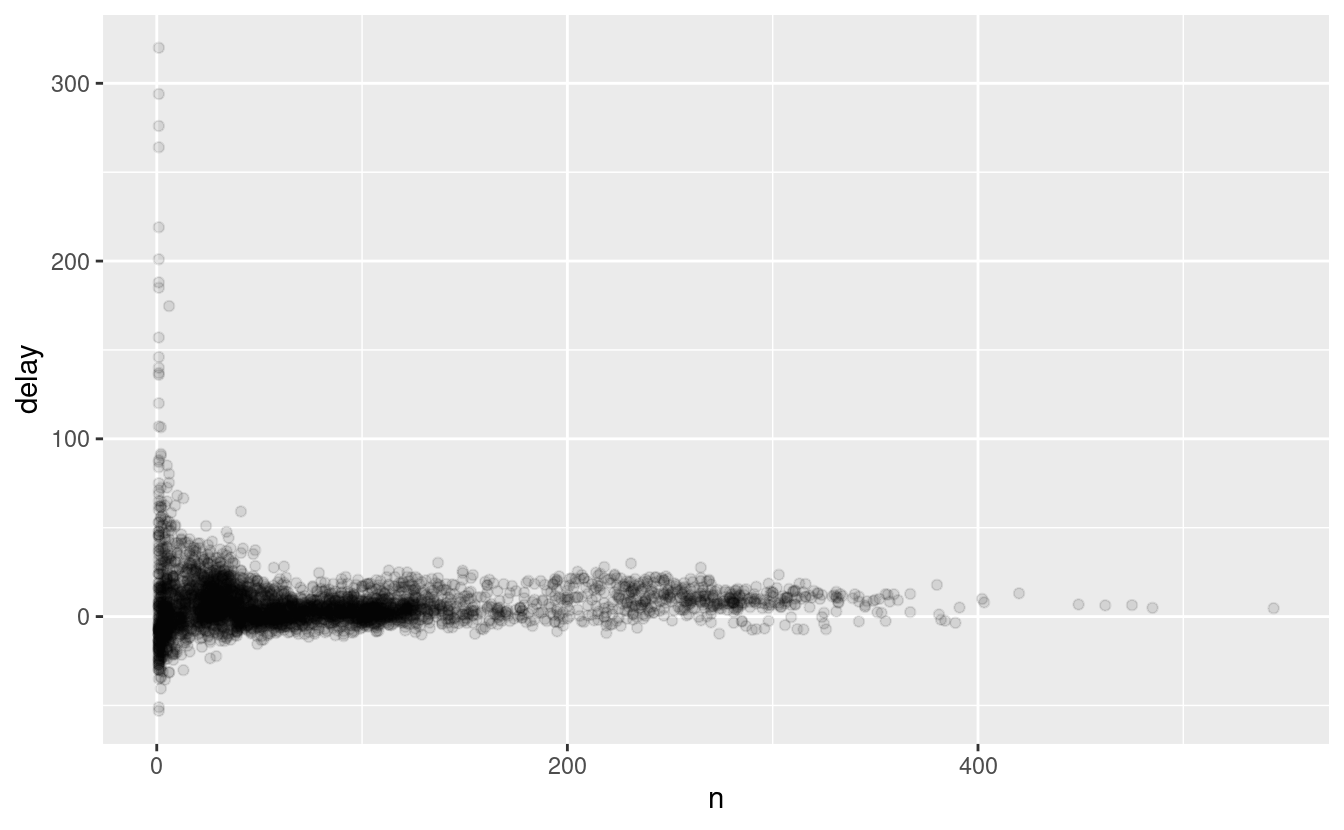
Non sorprende che ci sia una variazione molto maggiore nel ritardo medio quando ci sono pochi voli. La forma di questo grafico è molto caratteristica: ogni volta che tracciate una media (o un altro riassunto) rispetto alla dimensione del gruppo, vedrete che la variazione diminuisce all’aumentare della dimensione del campione.
Quando si guarda questo tipo di grafico, è spesso utile filtrare i gruppi con il più piccolo numero di osservazioni, in modo da poter vedere più il modello e meno la variazione estrema nei gruppi più piccoli. Questo è ciò che fa il seguente codice, oltre a mostrarvi un comodo schema per integrare ggplot2 nei flussi di dplyr. È un po’ doloroso dover passare da %>% a +, ma una volta che ci si prende la mano, è abbastanza comodo.
Suggerimento RStudio: un’utile scorciatoia da tastiera è Cmd/Ctrl + Shift + P. Questo rimanda il chunk precedentemente inviato dall’editor alla console. Questo è molto comodo quando stai (per esempio) esplorando il valore di n nell’esempio sopra. Invii l’intero blocco una volta con Cmd/Ctrl + Invio, poi modifichi il valore di n e premi Cmd/Ctrl + Shift + P per inviare nuovamente il blocco completo.
C’è un’altra variazione comune di questo tipo di schema. Guardiamo come la performance media dei battitori nel baseball è legata al numero di volte che sono alla battuta. Qui uso i dati del pacchetto Lahman per calcolare la media di battuta (numero di colpi / numero di tentativi) di ogni giocatore di baseball della Major League.
Quando tracciamo il grafico dell’abilità del battitore (misurata dalla media di battuta, ba) contro il numero di opportunità di colpire la palla (misurata dalla battuta, ab), si vedono due modelli:
Come sopra, la variazione del nostro aggregato diminuisce man mano che abbiamo più punti dati.
C’è una correlazione positiva tra abilità (
ba) e opportunità di colpire la palla (ab). Questo perché le squadre controllano chi può giocare, e ovviamente sceglieranno i loro migliori giocatori.
# Convertiamo in tibble in modo che si stampi bene
batting <- as_tibble(Lahman::Batting)
batters <- batting %>%
group_by(playerID) %>%
summarise(
ba = sum(H, na.rm = TRUE) / sum(AB, na.rm = TRUE),
ab = sum(AB, na.rm = TRUE)
)
batters %>%
filter(ab > 100) %>%
ggplot(mapping = aes(x = ab, y = ba)) +
geom_point() +
geom_smooth(se = FALSE)
#> `geom_smooth()` using method = 'gam' and formula = 'y ~ s(x, bs = "cs")'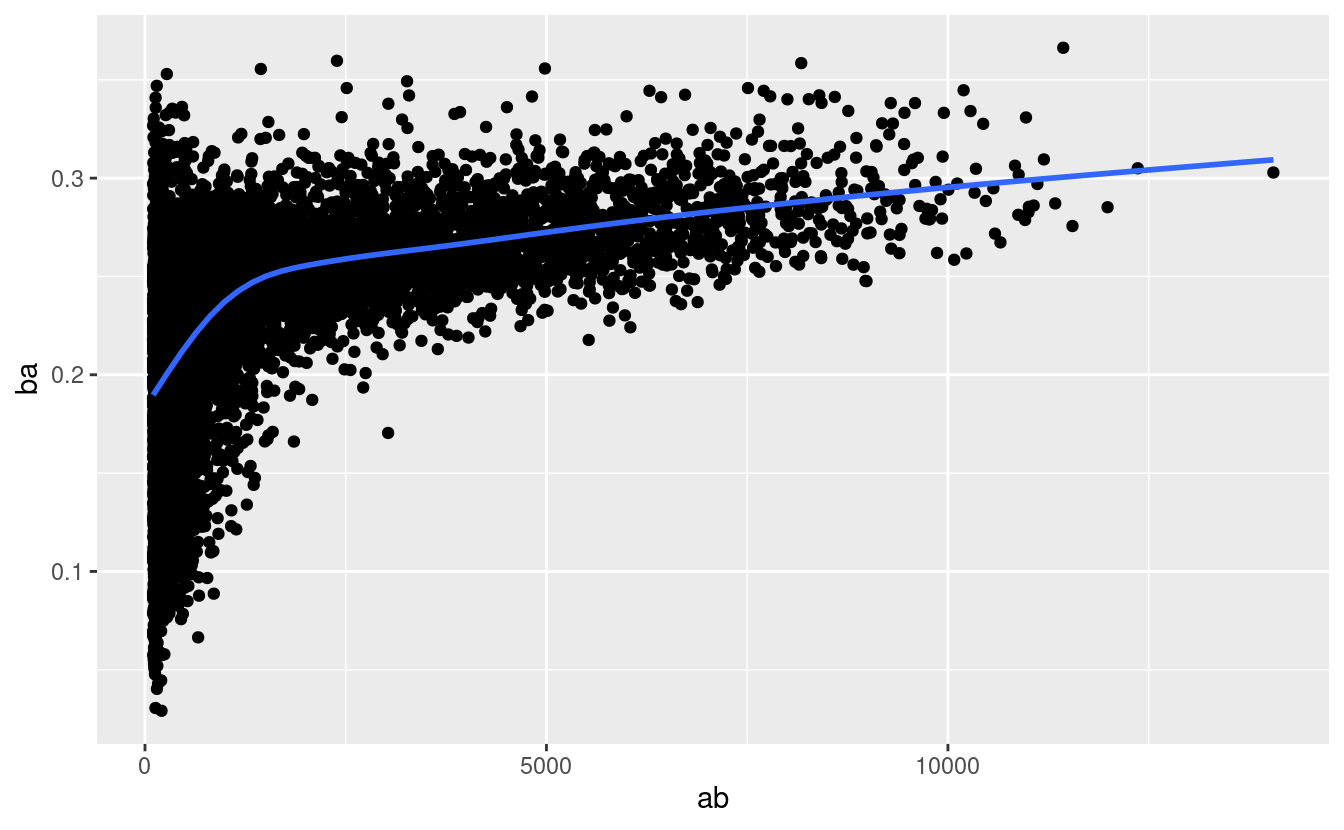
Questo ha anche importanti implicazioni per i ranghi. Se si ordina ingenuamente in base a desc(ba), le persone con le migliori medie di battuta sono chiaramente fortunate, non abili:
batters %>%
arrange(desc(ba))
#> # A tibble: 20,166 × 3
#> playerID ba ab
#> <chr> <dbl> <int>
#> 1 abramge01 1 1
#> 2 alberan01 1 1
#> 3 banisje01 1 1
#> 4 bartocl01 1 1
#> 5 bassdo01 1 1
#> 6 birasst01 1 2
#> # … with 20,160 more rowsPotete trovare una buona spiegazione di questo problema in http://varianceexplained.org/r/empirical_bayes_baseball/ e http://www.evanmiller.org/how-not-to-sort-by-average-rating.html.
5.6.4 Funzioni di riepilogo utili
Usare solo le medie, i conteggi e la somma può portarvi molto lontano, ma R fornisce molte altre utili funzioni di riepilogo:
-
Misure di posizione: abbiamo usato
mean(x), ma anchemedian(x)è utile. La media è la somma divisa per la lunghezza; la mediana è un valore dove il 50% dixè al di sopra di esso, e il 50% è al di sotto.A volte è utile combinare l’aggregazione con il sottoinsieme logico. Non abbiamo ancora parlato di questo tipo di sottoinsiemi, ma imparerete di più su di esso in sottoinsiemi.
not_cancelled %>% group_by(year, month, day) %>% summarise( avg_delay1 = mean(arr_delay), avg_delay2 = mean(arr_delay[arr_delay > 0]) # the average positive delay ) #> `summarise()` has grouped output by 'year', 'month'. You can override using the #> `.groups` argument. #> # A tibble: 365 × 5 #> # Groups: year, month [12] #> year month day avg_delay1 avg_delay2 #> <int> <int> <int> <dbl> <dbl> #> 1 2013 1 1 12.7 32.5 #> 2 2013 1 2 12.7 32.0 #> 3 2013 1 3 5.73 27.7 #> 4 2013 1 4 -1.93 28.3 #> 5 2013 1 5 -1.53 22.6 #> 6 2013 1 6 4.24 24.4 #> # … with 359 more rows -
Misure di spread:
sd(x),IQR(x),mad(x). La deviazione quadratica media, o deviazione standardsd(x), è la misura standard di diffusione. L’intervallo interquartileIQR(x)e la deviazione assoluta medianamad(x)sono equivalenti robusti che possono essere più utili se hai dei valori anomali.# Why is distance to some destinations more variable than to others? not_cancelled %>% group_by(dest) %>% summarise(distance_sd = sd(distance)) %>% arrange(desc(distance_sd)) #> # A tibble: 104 × 2 #> dest distance_sd #> <chr> <dbl> #> 1 EGE 10.5 #> 2 SAN 10.4 #> 3 SFO 10.2 #> 4 HNL 10.0 #> 5 SEA 9.98 #> 6 LAS 9.91 #> # … with 98 more rows -
Misure di rango:
min(x),quantile(x, 0.25),max(x). I quantili sono una generalizzazione della mediana. Per esempio,quantile(x, 0.25)troverà un valore dixche è maggiore del 25% dei valori, e inferiore al restante 75%.# When do the first and last flights leave each day? not_cancelled %>% group_by(year, month, day) %>% summarise( first = min(dep_time), last = max(dep_time) ) #> `summarise()` has grouped output by 'year', 'month'. You can override using the #> `.groups` argument. #> # A tibble: 365 × 5 #> # Groups: year, month [12] #> year month day first last #> <int> <int> <int> <int> <int> #> 1 2013 1 1 517 2356 #> 2 2013 1 2 42 2354 #> 3 2013 1 3 32 2349 #> 4 2013 1 4 25 2358 #> 5 2013 1 5 14 2357 #> 6 2013 1 6 16 2355 #> # … with 359 more rows -
Misure di posizione:
primo(x),n°(x, 2),ultimo(x). Queste funzionano in modo simile ax[1],x[2], ex[lunghezza(x)]ma vi permettono di impostare un valore predefinito valore se quella posizione non esiste (ad esempio, state cercando di ottenere il terzo elemento da un gruppo che ha solo due elementi). Per esempio, possiamo trovare la prima e l’ultima partenza per ogni giorno:not_cancelled %>% group_by(year, month, day) %>% summarise( first_dep = first(dep_time), last_dep = last(dep_time) ) #> `summarise()` has grouped output by 'year', 'month'. You can override using the #> `.groups` argument. #> # A tibble: 365 × 5 #> # Groups: year, month [12] #> year month day first_dep last_dep #> <int> <int> <int> <int> <int> #> 1 2013 1 1 517 2356 #> 2 2013 1 2 42 2354 #> 3 2013 1 3 32 2349 #> 4 2013 1 4 25 2358 #> 5 2013 1 5 14 2357 #> 6 2013 1 6 16 2355 #> # … with 359 more rowsQueste funzioni sono complementari al filtraggio sui ranghi. Il filtraggio dà tutte le variabili, con ogni osservazione in una riga separata:
not_cancelled %>% group_by(year, month, day) %>% mutate(r = min_rank(desc(dep_time))) %>% filter(r %in% range(r)) #> # A tibble: 770 × 20 #> # Groups: year, month, day [365] #> year month day dep_time sched_dep…¹ dep_d…² arr_t…³ sched…⁴ arr_d…⁵ carrier #> <int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr> #> 1 2013 1 1 517 515 2 830 819 11 UA #> 2 2013 1 1 2356 2359 -3 425 437 -12 B6 #> 3 2013 1 2 42 2359 43 518 442 36 B6 #> 4 2013 1 2 2354 2359 -5 413 437 -24 B6 #> 5 2013 1 3 32 2359 33 504 442 22 B6 #> 6 2013 1 3 2349 2359 -10 434 445 -11 B6 #> # … with 764 more rows, 10 more variables: flight <int>, tailnum <chr>, #> # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>, #> # minute <dbl>, time_hour <dttm>, r <int>, and abbreviated variable names #> # ¹sched_dep_time, ²dep_delay, ³arr_time, ⁴sched_arr_time, ⁵arr_delay -
Conteggi: Avete visto
n(), che non prende argomenti e restituisce la dimensione del gruppo corrente. Per contare il numero di valori non mancanti, usatesum(!is.na(x)). Per contare il numero di valori distinti (unici), usaten_distinct(x).# Which destinations have the most carriers? not_cancelled %>% group_by(dest) %>% summarise(carriers = n_distinct(carrier)) %>% arrange(desc(carriers)) #> # A tibble: 104 × 2 #> dest carriers #> <chr> <int> #> 1 ATL 7 #> 2 BOS 7 #> 3 CLT 7 #> 4 ORD 7 #> 5 TPA 7 #> 6 AUS 6 #> # … with 98 more rowsI conteggi sono così utili che dplyr fornisce un semplice aiuto se tutto ciò che si vuole è un conteggio:
not_cancelled %>% count(dest) #> # A tibble: 104 × 2 #> dest n #> <chr> <int> #> 1 ABQ 254 #> 2 ACK 264 #> 3 ALB 418 #> 4 ANC 8 #> 5 ATL 16837 #> 6 AUS 2411 #> # … with 98 more rowsPotete opzionalmente fornire una variabile di peso. Per esempio, potreste usare questo per “contare” (sommare) il numero totale di miglia volate da un aereo:
-
Conteggi e proporzioni di valori logici:
sum(x > 10),mean(y == 0). Quando viene usato con funzioni numeriche,TRUEè convertito in 1 eFALSEin 0. Questo rendesum()emean()molto utili: Lasomma(x)dà il numero diTRUEs inx, emean(x)dà la proporzione.# Quanti voli sono partiti prima delle 5 del mattino? (questi di solito # i voli indicano voli in ritardo del giorno precedente) not_cancelled %>% group_by(year, month, day) %>% summarise(n_early = sum(dep_time < 500)) #> `summarise()` has grouped output by 'year', 'month'. You can override using the #> `.groups` argument. #> # A tibble: 365 × 4 #> # Groups: year, month [12] #> year month day n_early #> <int> <int> <int> <int> #> 1 2013 1 1 0 #> 2 2013 1 2 3 #> 3 2013 1 3 4 #> 4 2013 1 4 3 #> 5 2013 1 5 3 #> 6 2013 1 6 2 #> # … with 359 more rows # Quale percentuale di voli è in ritardo di più di un'ora? not_cancelled %>% group_by(year, month, day) %>% summarise(hour_prop = mean(arr_delay > 60)) #> `summarise()` has grouped output by 'year', 'month'. You can override using the #> `.groups` argument. #> # A tibble: 365 × 4 #> # Groups: year, month [12] #> year month day hour_prop #> <int> <int> <int> <dbl> #> 1 2013 1 1 0.0722 #> 2 2013 1 2 0.0851 #> 3 2013 1 3 0.0567 #> 4 2013 1 4 0.0396 #> 5 2013 1 5 0.0349 #> 6 2013 1 6 0.0470 #> # … with 359 more rows
5.6.5 Raggruppare per variabili multiple
Quando si raggruppa per variabili multiple, ogni riepilogo si stacca da un livello del raggruppamento. Questo rende facile arrotolare progressivamente un set di dati:
daily <- group_by(flights, year, month, day)
(per_day <- summarise(daily, flights = n()))
#> `summarise()` has grouped output by 'year', 'month'. You can override using the
#> `.groups` argument.
#> # A tibble: 365 × 4
#> # Groups: year, month [12]
#> year month day flights
#> <int> <int> <int> <int>
#> 1 2013 1 1 842
#> 2 2013 1 2 943
#> 3 2013 1 3 914
#> 4 2013 1 4 915
#> 5 2013 1 5 720
#> 6 2013 1 6 832
#> # … with 359 more rows
(per_month <- summarise(per_day, flights = sum(flights)))
#> `summarise()` has grouped output by 'year'. You can override using the
#> `.groups` argument.
#> # A tibble: 12 × 3
#> # Groups: year [1]
#> year month flights
#> <int> <int> <int>
#> 1 2013 1 27004
#> 2 2013 2 24951
#> 3 2013 3 28834
#> 4 2013 4 28330
#> 5 2013 5 28796
#> 6 2013 6 28243
#> # … with 6 more rows
(per_year <- summarise(per_month, flights = sum(flights)))
#> # A tibble: 1 × 2
#> year flights
#> <int> <int>
#> 1 2013 336776Fate attenzione quando concatenate progressivamente i sommari: va bene per le somme e i conteggi, ma dovete pensare alla ponderazione di medie e varianze, e non è possibile farlo esattamente per le statistiche basate sui ranghi come la mediana. In altre parole, la somma delle somme per gruppi è la somma complessiva, ma la mediana delle mediane per gruppi non è la mediana complessiva.
5.6.6 De-raggruppamento
Se avete bisogno di rimuovere il raggruppamento e tornare alle operazioni su dati non raggruppati, usate ungroup().
5.6.7 Esercizi
-
Cerca almeno 5 modi diversi per valutare le caratteristiche di ritardo tipiche di un gruppo di voli. Considera i seguenti scenari:
Un volo è in anticipo di 15 minuti il 50% delle volte, e in ritardo di 15 minuti il 50% delle volte. delle volte.
Un volo è sempre in ritardo di 10 minuti.
Un volo è 30 minuti in anticipo il 50% del tempo e 30 minuti in ritardo il 50% del tempo. delle volte.
Il 99% delle volte un volo è in orario. L’1% delle volte è in ritardo di 2 ore.
Cos’è più importante: il ritardo di arrivo o il ritardo di partenza?
Trovate un altro approccio che vi dia lo stesso risultato di
not_cancelled %>% count(dest)enot_cancelled %>% count(tailnum, wt = distance)(senza usarecount()).La nostra definizione di voli cancellati (
is.na(dep_delay) | is.na(arr_delay)) è leggermente subottimale. Perché? Qual è la colonna più importante?Guarda il numero di voli cancellati al giorno. C’è un modello sottostante? La proporzione di voli cancellati è legata al ritardo medio?
Quale compagnia ha i peggiori ritardi? Sfida: puoi distinguere gli effetti effetti dei cattivi aeroporti rispetto alle cattive compagnie? Perché/perché no? (Suggerimento: pensa a
flights %>% group_by(carrier, dest) %>% summarise(n()))Cosa fa l’argomento
sortdicount(). Quando potreste usarlo?
5.7 Mutazioni raggruppate (e filtri)
Il raggruppamento è molto utile insieme a summarise(), ma si possono anche fare operazioni convenienti con mutate() e filter():
-
Trova i peggiori membri di ogni gruppo:
flights_sml %>% group_by(year, month, day) %>% filter(rank(desc(arr_delay)) < 10) #> # A tibble: 3,306 × 7 #> # Groups: year, month, day [365] #> year month day dep_delay arr_delay distance air_time #> <int> <int> <int> <dbl> <dbl> <dbl> <dbl> #> 1 2013 1 1 853 851 184 41 #> 2 2013 1 1 290 338 1134 213 #> 3 2013 1 1 260 263 266 46 #> 4 2013 1 1 157 174 213 60 #> 5 2013 1 1 216 222 708 121 #> 6 2013 1 1 255 250 589 115 #> # … with 3,300 more rows -
Trova tutti i gruppi più grandi di una soglia:
popular_dests <- flights %>% group_by(dest) %>% filter(n() > 365) popular_dests #> # A tibble: 332,577 × 19 #> # Groups: dest [77] #> year month day dep_time sched_dep…¹ dep_d…² arr_t…³ sched…⁴ arr_d…⁵ carrier #> <int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr> #> 1 2013 1 1 517 515 2 830 819 11 UA #> 2 2013 1 1 533 529 4 850 830 20 UA #> 3 2013 1 1 542 540 2 923 850 33 AA #> 4 2013 1 1 544 545 -1 1004 1022 -18 B6 #> 5 2013 1 1 554 600 -6 812 837 -25 DL #> 6 2013 1 1 554 558 -4 740 728 12 UA #> # … with 332,571 more rows, 9 more variables: flight <int>, tailnum <chr>, #> # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>, #> # minute <dbl>, time_hour <dttm>, and abbreviated variable names #> # ¹sched_dep_time, ²dep_delay, ³arr_time, ⁴sched_arr_time, ⁵arr_delay -
Standardizzare per calcolare le metriche per gruppo:
popular_dests %>% filter(arr_delay > 0) %>% mutate(prop_delay = arr_delay / sum(arr_delay)) %>% select(year:day, dest, arr_delay, prop_delay) #> # A tibble: 131,106 × 6 #> # Groups: dest [77] #> year month day dest arr_delay prop_delay #> <int> <int> <int> <chr> <dbl> <dbl> #> 1 2013 1 1 IAH 11 0.000111 #> 2 2013 1 1 IAH 20 0.000201 #> 3 2013 1 1 MIA 33 0.000235 #> 4 2013 1 1 ORD 12 0.0000424 #> 5 2013 1 1 FLL 19 0.0000938 #> 6 2013 1 1 ORD 8 0.0000283 #> # … with 131,100 more rows
Un filtro raggruppato è una mutazione raggruppata seguita da un filtro non raggruppato. Generalmente li evito tranne che per manipolazioni rapide e sporche: altrimenti è difficile controllare di aver fatto la manipolazione correttamente.
Le funzioni che funzionano più naturalmente nei mutate raggruppati e nei filtri sono note come funzioni finestra (rispetto alle funzioni di sintesi usate per i sommari). Puoi imparare di più sulle utili funzioni finestra nella vignetta corrispondente: vignette("window-functions").
5.7.1 Esercizi
Fai riferimento alle liste di funzioni utili per mutare e filtrare. Descrivete come cambia ogni operazione quando la combinate con il raggruppamento.
Quale aereo (
tailnum) ha il peggior record di puntualità?A che ora del giorno dovresti volare se vuoi evitare il più possibile i ritardi? possibile?
Per ogni destinazione, calcola i minuti totali di ritardo. Per ogni volo, calcola la proporzione del ritardo totale per la sua destinazione.
I ritardi sono tipicamente correlati temporalmente: anche una volta che il problema che il problema che ha causato il ritardo iniziale è stato risolto, i voli successivi sono ritardati per permettere ai voli precedenti di partire. Utilizzando
lag(), esplorate come il ritardo di un volo sia correlato al ritardo del volo immediatamente precedente.Guarda ogni destinazione. Potete trovare voli che sono sospettosamente veloci? (cioè voli che rappresentano un potenziale errore di inserimento dati). 2. Calcola il tempo di volo di un volo rispetto al volo più breve per quella destinazione. Quali voli hanno subito più ritardi in volo?
Trova tutte le destinazioni che sono volate da almeno due compagnie. Usa questa informazioni per classificare i vettori.
Per ogni aereo, conti il numero di voli prima del primo ritardo superiore a 1 ora.