13 Dati relazionali
13.1 Introduzione
È raro che un’analisi dei dati coinvolga solo una singola tabella di dati. Tipicamente si hanno molte tabelle di dati, e bisogna combinarle per rispondere alle domande che interessano. Collettivamente, più tabelle di dati sono chiamate dati relazionali perché sono importanti le relazioni, non solo i singoli insiemi di dati.
Le relazioni sono sempre definite tra una coppia di tabelle. Tutte le altre relazioni sono costruite a partire da questa semplice idea: le relazioni di tre o più tabelle sono sempre una proprietà delle relazioni tra ogni coppia. A volte entrambi gli elementi di una coppia possono essere la stessa tabella! Questo è necessario se, per esempio, avete una tabella di persone, e ogni persona ha un riferimento ai suoi genitori.
Per lavorare con i dati relazionali avete bisogno di verbi che lavorino con coppie di tabelle. Ci sono tre famiglie di verbi progettati per lavorare con i dati relazionali:
Mutating joins, che aggiungono nuove variabili ad un frame di dati dalla corrispondenza osservazioni in un altro.
Filtering joins, che filtrano le osservazioni di un frame di dati in base se corrispondono o meno ad un’osservazione nell’altra tabella.
Operazioni di set, che trattano le osservazioni come se fossero elementi di un set.
Il posto più comune per trovare dati relazionali è in un sistema di gestione di database relazionali (o RDBMS), un termine che comprende quasi tutti i moderni database. Se avete usato un database prima, avete quasi certamente usato SQL. Se è così, i concetti di questo capitolo dovrebbero esservi familiari, anche se la loro espressione in dplyr è un po’ diversa. In generale, dplyr è un po’ più facile da usare di SQL perché dplyr è specializzato nell’analisi dei dati: rende più facili le comuni operazioni di analisi dei dati, a spese di rendere più difficile fare altre cose che non sono comunemente necessarie per l’analisi dei dati.
13.2 nycflights13
Useremo il pacchetto nycflights13 per imparare i dati relazionali. nycflights13 contiene quattro tibbie che sono collegate alla tabella flights che avete usato in trasformazione:
-
airlinesti permette di cercare il nome completo del vettore dal suo codice abbreviato:airlines #> # A tibble: 16 × 2 #> carrier name #> <chr> <chr> #> 1 9E Endeavor Air Inc. #> 2 AA American Airlines Inc. #> 3 AS Alaska Airlines Inc. #> 4 B6 JetBlue Airways #> 5 DL Delta Air Lines Inc. #> 6 EV ExpressJet Airlines Inc. #> # … with 10 more rows -
airportsdà informazioni su ogni aeroporto, identificato dal codice aeroportualefaa:airports #> # A tibble: 1,458 × 8 #> faa name lat lon alt tz dst tzone #> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr> #> 1 04G Lansdowne Airport 41.1 -80.6 1044 -5 A America/Ne… #> 2 06A Moton Field Municipal Airport 32.5 -85.7 264 -6 A America/Ch… #> 3 06C Schaumburg Regional 42.0 -88.1 801 -6 A America/Ch… #> 4 06N Randall Airport 41.4 -74.4 523 -5 A America/Ne… #> 5 09J Jekyll Island Airport 31.1 -81.4 11 -5 A America/Ne… #> 6 0A9 Elizabethton Municipal Airport 36.4 -82.2 1593 -5 A America/Ne… #> # … with 1,452 more rows -
planesdà informazioni su ogni aereo, identificato dal suotailnum:planes #> # A tibble: 3,322 × 9 #> tailnum year type manuf…¹ model engines seats speed engine #> <chr> <int> <chr> <chr> <chr> <int> <int> <int> <chr> #> 1 N10156 2004 Fixed wing multi engine EMBRAER EMB-… 2 55 NA Turbo… #> 2 N102UW 1998 Fixed wing multi engine AIRBUS… A320… 2 182 NA Turbo… #> 3 N103US 1999 Fixed wing multi engine AIRBUS… A320… 2 182 NA Turbo… #> 4 N104UW 1999 Fixed wing multi engine AIRBUS… A320… 2 182 NA Turbo… #> 5 N10575 2002 Fixed wing multi engine EMBRAER EMB-… 2 55 NA Turbo… #> 6 N105UW 1999 Fixed wing multi engine AIRBUS… A320… 2 182 NA Turbo… #> # … with 3,316 more rows, and abbreviated variable name ¹manufacturer -
weatherdà il meteo in ogni aeroporto di NYC per ogni ora:weather #> # A tibble: 26,115 × 15 #> origin year month day hour temp dewp humid wind_dir wind_speed wind_gust #> <chr> <int> <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> #> 1 EWR 2013 1 1 1 39.0 26.1 59.4 270 10.4 NA #> 2 EWR 2013 1 1 2 39.0 27.0 61.6 250 8.06 NA #> 3 EWR 2013 1 1 3 39.0 28.0 64.4 240 11.5 NA #> 4 EWR 2013 1 1 4 39.9 28.0 62.2 250 12.7 NA #> 5 EWR 2013 1 1 5 39.0 28.0 64.4 260 12.7 NA #> 6 EWR 2013 1 1 6 37.9 28.0 67.2 240 11.5 NA #> # … with 26,109 more rows, and 4 more variables: precip <dbl>, pressure <dbl>, #> # visib <dbl>, time_hour <dttm>
Un modo per mostrare le relazioni tra le diverse tabelle è un disegno:
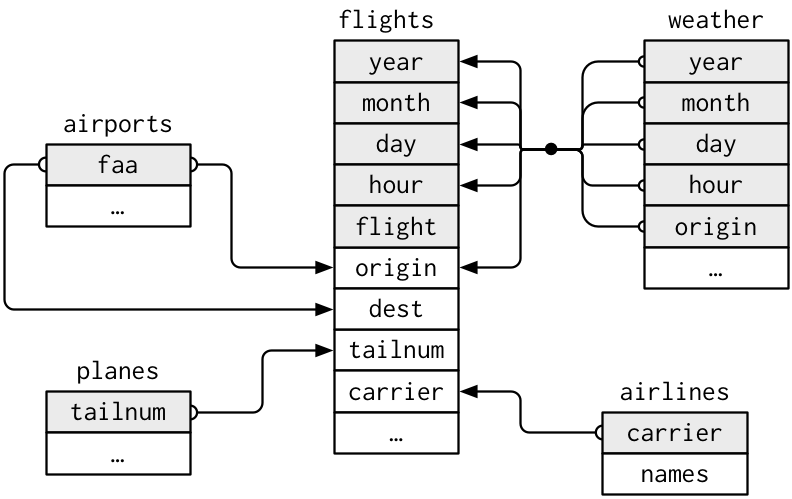
Questo diagramma è un po’ travolgente, ma è semplice rispetto ad alcuni che vedrete in natura! La chiave per capire diagrammi come questo è ricordare che ogni relazione riguarda sempre una coppia di tabelle. Non c’è bisogno di capire tutto, basta capire la catena di relazioni tra le tabelle a cui si è interessati.
Per nycflights13:
flightssi connette aplanesattraverso una singola variabile,tailnum.flightssi connette aairlinesattraverso la variabilecarrier.flightssi connette aairportsin due modi: attraverso le variabilioriginedest.I voli si connettono al meteo attraverso la variabile
origin(la località), eyear,month,dayehour(il tempo).
13.2.1 Esercizi
Immagina di voler disegnare (approssimativamente) la rotta che ogni aereo vola da sua origine alla sua destinazione. Di quali variabili avresti bisogno? Quali tabelle avreste bisogno di combinare?
Ho dimenticato di disegnare la relazione tra
weathereairports. Qual è la relazione e come dovrebbe apparire nel diagramma?weathercontiene solo informazioni per gli aeroporti di origine (NYC). Se contenesse le informazioni meteo per tutti gli aeroporti degli USA, quale ulteriore relazione aggiuntiva definirebbe conflights?Sappiamo che alcuni giorni dell’anno sono “speciali”, e meno persone del persone del solito volano in quei giorni. Come potresti rappresentare questi dati come un frame di dati? Quali sarebbero le chiavi primarie di quella tabella? Come si connetterebbe alle tabelle esistenti?
13.3 Chiavi
Le variabili usate per collegare ogni coppia di tabelle sono chiamate chiavi. Una chiave è una variabile (o un insieme di variabili) che identifica univocamente un’osservazione. In casi semplici, una singola variabile è sufficiente per identificare un’osservazione. Per esempio, ogni piano è identificato univocamente dal suo tailnum. In altri casi, possono essere necessarie più variabili. Per esempio, per identificare un’osservazione in weather sono necessarie cinque variabili: year, month, day, hour e origin.
Ci sono due tipi di chiavi:
Una chiave primaria identifica univocamente un’osservazione nella propria tabella. Per esempio,
planes$tailnumè una chiave primaria perché identifica univocamente ogni aereo nella tabellaplanes.Una chiave esterna identifica univocamente un’osservazione in un’altra tabella. Per esempio,
flights$tailnumè una chiave esterna perché appare nella tabella tabellaflightsdove corrisponde ad ogni volo ad un unico aereo.
Una variabile può essere sia una chiave primaria e una chiave esterna. Per esempio, origin fa parte della chiave primaria weather ed è anche una chiave esterna per la tabella airports.
Una volta che hai identificato le chiavi primarie nelle tue tabelle, è una buona pratica verificare che esse identifichino davvero in modo univoco ogni osservazione. Un modo per farlo è quello di count() le chiavi primarie e cercare le voci dove n è maggiore di uno:
planes %>%
count(tailnum) %>%
filter(n > 1)
#> # A tibble: 0 × 2
#> # … with 2 variables: tailnum <chr>, n <int>
weather %>%
count(year, month, day, hour, origin) %>%
filter(n > 1)
#> # A tibble: 3 × 6
#> year month day hour origin n
#> <int> <int> <int> <int> <chr> <int>
#> 1 2013 11 3 1 EWR 2
#> 2 2013 11 3 1 JFK 2
#> 3 2013 11 3 1 LGA 2A volte una tabella non ha una chiave primaria esplicita: ogni riga è un’osservazione, ma nessuna combinazione di variabili la identifica in modo affidabile. Per esempio, qual è la chiave primaria nella tabella flights? Si potrebbe pensare che sia la data più il numero di volo o di coda, ma nessuno dei due è unico:
flights %>%
count(year, month, day, flight) %>%
filter(n > 1)
#> # A tibble: 29,768 × 5
#> year month day flight n
#> <int> <int> <int> <int> <int>
#> 1 2013 1 1 1 2
#> 2 2013 1 1 3 2
#> 3 2013 1 1 4 2
#> 4 2013 1 1 11 3
#> 5 2013 1 1 15 2
#> 6 2013 1 1 21 2
#> # … with 29,762 more rows
flights %>%
count(year, month, day, tailnum) %>%
filter(n > 1)
#> # A tibble: 64,928 × 5
#> year month day tailnum n
#> <int> <int> <int> <chr> <int>
#> 1 2013 1 1 N0EGMQ 2
#> 2 2013 1 1 N11189 2
#> 3 2013 1 1 N11536 2
#> 4 2013 1 1 N11544 3
#> 5 2013 1 1 N11551 2
#> 6 2013 1 1 N12540 2
#> # … with 64,922 more rowsQuando ho iniziato a lavorare con questi dati, avevo ingenuamente supposto che ogni numero di volo sarebbe stato usato solo una volta al giorno: questo avrebbe reso molto più facile comunicare i problemi con un volo specifico. Purtroppo non è così! Se una tabella manca di una chiave primaria, a volte è utile aggiungerne una con mutate() e row_number(). Questo rende più facile far combaciare le osservazioni se avete fatto qualche filtraggio e volete ricontrollare i dati originali. Questa è chiamata una _chiave surrogata__.
Una chiave primaria e la corrispondente chiave esterna in un’altra tabella formano una relazione. Le relazioni sono tipicamente uno-a-molti. Per esempio, ogni volo ha un aereo, ma ogni aereo ha molti voli. In altri dati, occasionalmente vedrete una relazione 1 a 1. Potete pensare a questo come ad un caso speciale di 1-a-molti. Potete modellare le relazioni molti-a-molti con una relazione molti-a-1 più una relazione 1-a-molti. Per esempio, in questi dati c’è una relazione molti-a-molti tra compagnie aeree e aeroporti: ogni compagnia aerea vola in molti aeroporti; ogni aeroporto ospita molte compagnie aeree.
13.3.1 Esercizi
Aggiungere una chiave surrogata a
flights.-
Identifica le chiavi nei seguenti set di dati
-
Lahman::Batting, -
babynames::babynames. -
nasaweather::atmos. fueleconomy::vehicles-
ggplot2::diamonds.
(Potrebbe essere necessario installare alcuni pacchetti e leggere un po’ di documentazione).
-
-
Disegna un diagramma che illustri le connessioni tra le tabelle
Batting,PeopleeSalariesnel pacchetto Lahman. Disegna un altro diagramma che mostra la relazione traPeople,Managers,AwardsManagers.Come caratterizzeresti la relazione tra le tabelle
Batting,PitchingeFielding?
13.4 Mutating joins
Il primo strumento che vedremo per combinare una coppia di tabelle è la mutating join. Una mutating join permette di combinare le variabili di due tabelle. Prima abbina le osservazioni in base alle loro chiavi, poi copia le variabili da una tabella all’altra.
Come mutate(), le funzioni di join aggiungono le variabili a destra, quindi se avete già molte variabili, le nuove variabili non verranno stampate. Per questi esempi, renderemo più facile vedere cosa succede negli esempi creando un set di dati più ristretto:
flights2 <- flights %>%
select(year:day, hour, origin, dest, tailnum, carrier)
flights2
#> # A tibble: 336,776 × 8
#> year month day hour origin dest tailnum carrier
#> <int> <int> <int> <dbl> <chr> <chr> <chr> <chr>
#> 1 2013 1 1 5 EWR IAH N14228 UA
#> 2 2013 1 1 5 LGA IAH N24211 UA
#> 3 2013 1 1 5 JFK MIA N619AA AA
#> 4 2013 1 1 5 JFK BQN N804JB B6
#> 5 2013 1 1 6 LGA ATL N668DN DL
#> 6 2013 1 1 5 EWR ORD N39463 UA
#> # … with 336,770 more rows(Ricordate, quando siete in RStudio, potete anche usare View() per evitare questo problema).
Immaginate di voler aggiungere il nome completo della compagnia aerea ai dati di flights2. Potete combinare i data frame airlines e flights2 con left_join():
flights2 %>%
select(-origin, -dest) %>%
left_join(airlines, by = "carrier")
#> # A tibble: 336,776 × 7
#> year month day hour tailnum carrier name
#> <int> <int> <int> <dbl> <chr> <chr> <chr>
#> 1 2013 1 1 5 N14228 UA United Air Lines Inc.
#> 2 2013 1 1 5 N24211 UA United Air Lines Inc.
#> 3 2013 1 1 5 N619AA AA American Airlines Inc.
#> 4 2013 1 1 5 N804JB B6 JetBlue Airways
#> 5 2013 1 1 6 N668DN DL Delta Air Lines Inc.
#> 6 2013 1 1 5 N39463 UA United Air Lines Inc.
#> # … with 336,770 more rowsIl risultato dell’unione delle compagnie aeree a flights2 è una variabile aggiuntiva: name. Questo è il motivo per cui chiamo questo tipo di join un join mutante. In questo caso, avreste potuto arrivare allo stesso punto usando mutate() e il subsetting di base di R:
flights2 %>%
select(-origin, -dest) %>%
mutate(name = airlines$name[match(carrier, airlines$carrier)])
#> # A tibble: 336,776 × 7
#> year month day hour tailnum carrier name
#> <int> <int> <int> <dbl> <chr> <chr> <chr>
#> 1 2013 1 1 5 N14228 UA United Air Lines Inc.
#> 2 2013 1 1 5 N24211 UA United Air Lines Inc.
#> 3 2013 1 1 5 N619AA AA American Airlines Inc.
#> 4 2013 1 1 5 N804JB B6 JetBlue Airways
#> 5 2013 1 1 6 N668DN DL Delta Air Lines Inc.
#> 6 2013 1 1 5 N39463 UA United Air Lines Inc.
#> # … with 336,770 more rowsMa questo è difficile da generalizzare quando si ha bisogno di abbinare più variabili, e richiede una lettura attenta per capire l’intento generale.
Le sezioni seguenti spiegano, in dettaglio, come funzionano le mutating joins. Comincerete imparando un’utile rappresentazione visiva delle unioni. Poi la useremo per spiegare le quattro funzioni di mutating join: l’inner join e le tre outer join. Quando si lavora con dati reali, le chiavi non sempre identificano in modo univoco le osservazioni, quindi parleremo di cosa succede quando non c’è una corrispondenza unica. Infine, imparerete come dire a dplyr quali variabili sono le chiavi per una data unione.
13.4.1 Capire le unioni
Per aiutarvi ad imparare come funzionano le join, userò una rappresentazione visiva:
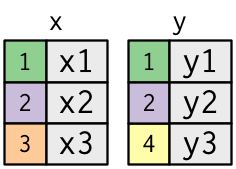
x <- tribble(
~key, ~val_x,
1, "x1",
2, "x2",
3, "x3"
)
y <- tribble(
~key, ~val_y,
1, "y1",
2, "y2",
4, "y3"
)La colonna colorata rappresenta la variabile “chiave”: questa è usata per abbinare le righe tra le tabelle. La colonna grigia rappresenta la colonna “valore” che viene portata con sé per il viaggio. In questi esempi mostrerò una singola variabile chiave, ma l’idea si generalizza in modo diretto a chiavi multiple e valori multipli.
Un join è un modo di collegare ogni riga in x a zero, una o più righe in y. Il diagramma seguente mostra ogni potenziale corrispondenza come un’intersezione di una coppia di linee.
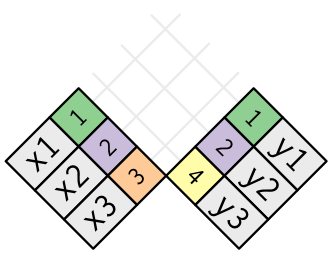
(Se guardate attentamente, potreste notare che abbiamo cambiato l’ordine delle colonne chiave e valore in x. Questo è per enfatizzare che i join corrispondono in base alla chiave; il valore è solo portato con sé per il viaggio).
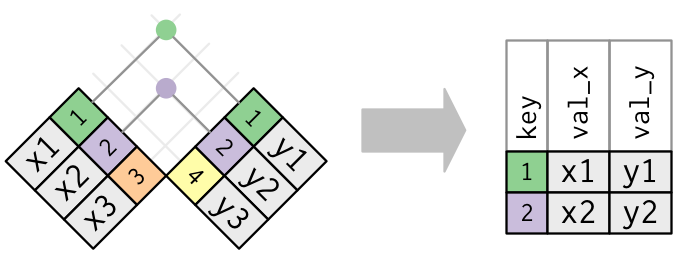
In un vero join, le corrispondenze saranno indicate con dei punti. Il numero di punti = il numero di corrispondenze = il numero di righe nell’output.
13.4.2 Inner join
Il tipo più semplice di join è l’inner join. Un join interno abbina coppie di osservazioni ogni volta che le loro chiavi sono uguali:
(Per essere precisi, questa è una equijoin interna perché le chiavi sono abbinate usando l’operatore di uguaglianza. Dato che la maggior parte delle unioni sono equijoin, di solito lasciamo perdere questa specificazione).
L’output di un join interno è un nuovo data frame che contiene la chiave, i valori x e i valori y. Usiamo by per dire a dplyr quale variabile è la chiave:
x %>%
inner_join(y, by = "key")
#> # A tibble: 2 × 3
#> key val_x val_y
#> <dbl> <chr> <chr>
#> 1 1 x1 y1
#> 2 2 x2 y2La proprietà più importante di un inner join è che le righe non abbinate non sono incluse nel risultato. Questo significa che generalmente le inner joins non sono appropriate per l’uso in analisi perché è troppo facile perdere osservazioni.
13.4.3 Outer joins
Un inner join mantiene le osservazioni che appaiono in entrambe le tabelle. Una outer join mantiene le osservazioni che appaiono in almeno una delle tabelle. Ci sono tre tipi di outer join:
- Una left join mantiene tutte le osservazioni in
x. - Un joint a destra mantiene tutte le osservazioni in
y. - Un full join mantiene tutte le osservazioni in
xey.
Questi join funzionano aggiungendo un’osservazione “virtuale” addizionale ad ogni tabella. Questa osservazione ha una chiave che corrisponde sempre (se nessun’altra chiave corrisponde), e un valore riempito con NA.
Graficamente, questo appare come:
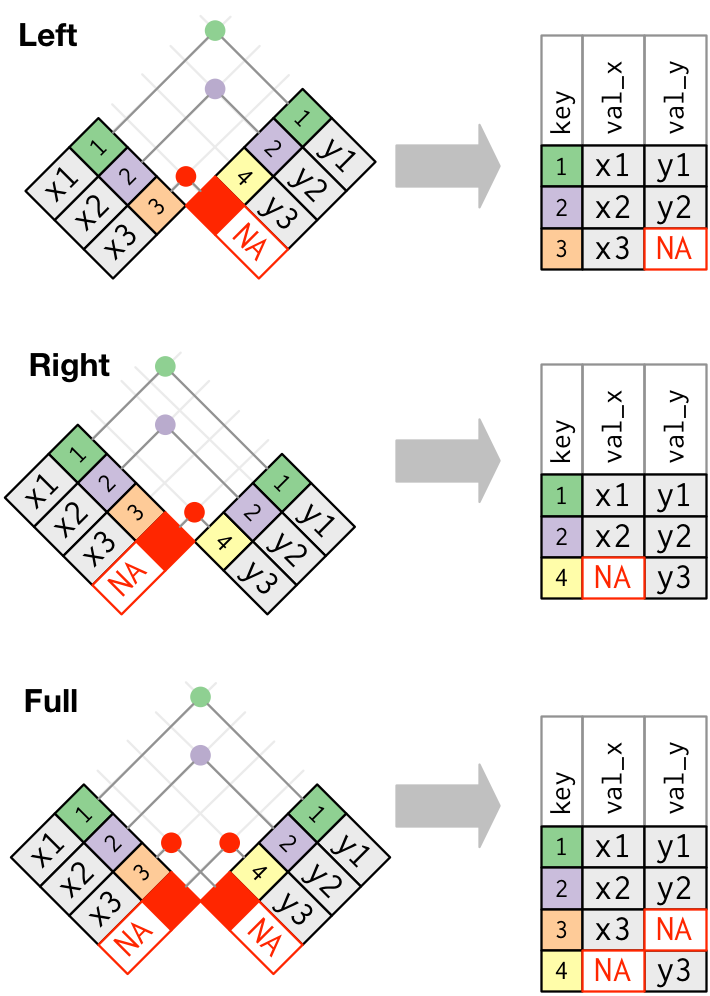
L’unione più comunemente usata è l’unione a sinistra: la si usa ogni volta che si cercano dati aggiuntivi da un’altra tabella, perché conserva le osservazioni originali anche quando non c’è una corrispondenza. L’unione a sinistra dovrebbe essere la tua unione di default: usala a meno che tu non abbia una forte ragione per preferire una delle altre.
Un altro modo per rappresentare i diversi tipi di join è un diagramma di Venn:
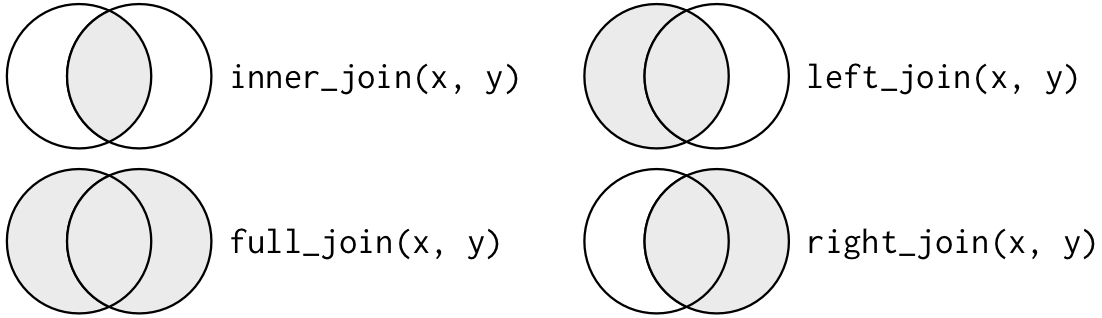
Tuttavia, questa non è una grande rappresentazione. Potrebbe rinfrescarvi la memoria su quale join conserva le osservazioni in quale tabella, ma soffre di una grande limitazione: un diagramma di Venn non può mostrare cosa succede quando le chiavi non identificano univocamente un’osservazione.
13.4.4 Chiavi duplicate
Finora tutti i diagrammi hanno assunto che le chiavi siano uniche. Ma questo non è sempre il caso. Questa sezione spiega cosa succede quando le chiavi non sono uniche. Ci sono due possibilità:
-
Una tabella ha chiavi duplicate. Questo è utile quando vuoi aggiungere ulteriori informazioni, dato che tipicamente c’è una relazione uno-a-molti.
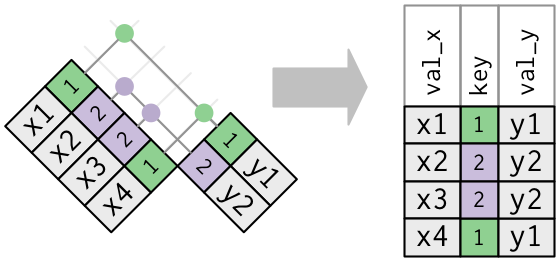
Notate che ho messo la colonna chiave in una posizione leggermente diversa nell’output. Questo riflette il fatto che la chiave è una chiave primaria in
ye una chiave esterna inx. -
Entrambe le tabelle hanno chiavi duplicate. Questo è di solito un errore perché in nessuna delle due tabelle le chiavi identificano univocamente un’osservazione. Quando si uniscono chiavi duplicate, si ottengono tutte le combinazioni possibili, il prodotto cartesiano:
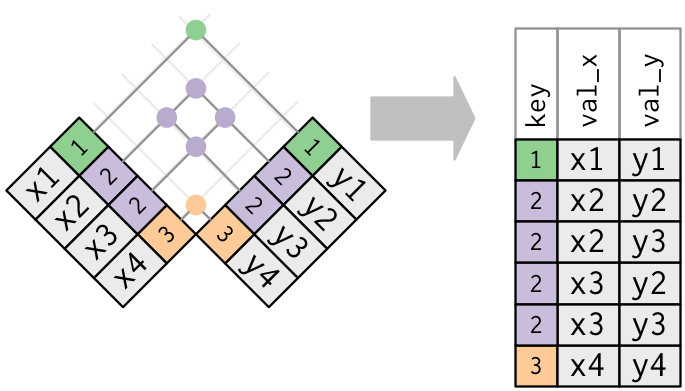
x <- tribble( ~key, ~val_x, 1, "x1", 2, "x2", 2, "x3", 3, "x4" ) y <- tribble( ~key, ~val_y, 1, "y1", 2, "y2", 2, "y3", 3, "y4" ) left_join(x, y, by = "key") #> Warning in left_join(x, y, by = "key"): Each row in `x` is expected to match at most 1 row in `y`. #> ℹ Row 2 of `x` matches multiple rows. #> ℹ If multiple matches are expected, set `multiple = "all"` to silence this #> warning. #> # A tibble: 6 × 3 #> key val_x val_y #> <dbl> <chr> <chr> #> 1 1 x1 y1 #> 2 2 x2 y2 #> 3 2 x2 y3 #> 4 2 x3 y2 #> 5 2 x3 y3 #> 6 3 x4 y4
13.4.5 Definizione delle colonne chiave
Finora, le coppie di tabelle sono sempre state unite da una singola variabile, e questa variabile ha lo stesso nome in entrambe le tabelle. Questo vincolo è stato codificato da by = "key". Puoi usare altri valori per by per collegare le tabelle in altri modi:
-
Il valore predefinito,
by = NULL, usa tutte le variabili che appaiono in entrambe le tabelle, il cosiddetto natural join. Per esempio, le tabelle dei voli e del meteo corrispondono sulle loro variabili comuni:year,month,day,houreorigin.flights2 %>% left_join(weather) #> Joining with `by = join_by(year, month, day, hour, origin)` #> # A tibble: 336,776 × 18 #> year month day hour origin dest tailnum carrier temp dewp humid wind_…¹ #> <int> <int> <int> <dbl> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> #> 1 2013 1 1 5 EWR IAH N14228 UA 39.0 28.0 64.4 260 #> 2 2013 1 1 5 LGA IAH N24211 UA 39.9 25.0 54.8 250 #> 3 2013 1 1 5 JFK MIA N619AA AA 39.0 27.0 61.6 260 #> 4 2013 1 1 5 JFK BQN N804JB B6 39.0 27.0 61.6 260 #> 5 2013 1 1 6 LGA ATL N668DN DL 39.9 25.0 54.8 260 #> 6 2013 1 1 5 EWR ORD N39463 UA 39.0 28.0 64.4 260 #> # … with 336,770 more rows, 6 more variables: wind_speed <dbl>, #> # wind_gust <dbl>, precip <dbl>, pressure <dbl>, visib <dbl>, #> # time_hour <dttm>, and abbreviated variable name ¹wind_dir -
Un vettore di caratteri,
by = "x". Questo è come un join naturale, ma usa solo alcune delle variabili comuni. Per esempio,flightseplaneshanno variabiliyear, ma significano cose diverse, quindi vogliamo unire solo pertailnum.flights2 %>% left_join(planes, by = "tailnum") #> # A tibble: 336,776 × 16 #> year.x month day hour origin dest tailnum carrier year.y type manuf…¹ #> <int> <int> <int> <dbl> <chr> <chr> <chr> <chr> <int> <chr> <chr> #> 1 2013 1 1 5 EWR IAH N14228 UA 1999 Fixed wi… BOEING #> 2 2013 1 1 5 LGA IAH N24211 UA 1998 Fixed wi… BOEING #> 3 2013 1 1 5 JFK MIA N619AA AA 1990 Fixed wi… BOEING #> 4 2013 1 1 5 JFK BQN N804JB B6 2012 Fixed wi… AIRBUS #> 5 2013 1 1 6 LGA ATL N668DN DL 1991 Fixed wi… BOEING #> 6 2013 1 1 5 EWR ORD N39463 UA 2012 Fixed wi… BOEING #> # … with 336,770 more rows, 5 more variables: model <chr>, engines <int>, #> # seats <int>, speed <int>, engine <chr>, and abbreviated variable name #> # ¹manufacturerSi noti che le variabili
year(che appaiono in entrambi i data frame di input, ma non sono costrette ad essere uguali) sono disambiguate nell’output con un suffisso. -
Un vettore di caratteri con nome:
by = c("a" = "b"). Questo corrisponde alla variabileanella tabellaxalla variabilebnella tabellay. Le variabili daxsaranno usate nell’output.Per esempio, se vogliamo disegnare una mappa abbiamo bisogno di combinare i dati dei voli con i dati degli aeroporti che contengono la posizione (
latelon) di ogni aeroporto. Ogni volo ha unairportdi origine e uno di destinazione, quindi bisogno di specificare a quale vogliamo unire i dati:flights2 %>% left_join(airports, c("dest" = "faa")) #> # A tibble: 336,776 × 15 #> year month day hour origin dest tailnum carrier name lat lon alt #> <int> <int> <int> <dbl> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> #> 1 2013 1 1 5 EWR IAH N14228 UA George… 30.0 -95.3 97 #> 2 2013 1 1 5 LGA IAH N24211 UA George… 30.0 -95.3 97 #> 3 2013 1 1 5 JFK MIA N619AA AA Miami … 25.8 -80.3 8 #> 4 2013 1 1 5 JFK BQN N804JB B6 <NA> NA NA NA #> 5 2013 1 1 6 LGA ATL N668DN DL Hartsf… 33.6 -84.4 1026 #> 6 2013 1 1 5 EWR ORD N39463 UA Chicag… 42.0 -87.9 668 #> # … with 336,770 more rows, and 3 more variables: tz <dbl>, dst <chr>, #> # tzone <chr> flights2 %>% left_join(airports, c("origin" = "faa")) #> # A tibble: 336,776 × 15 #> year month day hour origin dest tailnum carrier name lat lon alt #> <int> <int> <int> <dbl> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> #> 1 2013 1 1 5 EWR IAH N14228 UA Newark… 40.7 -74.2 18 #> 2 2013 1 1 5 LGA IAH N24211 UA La Gua… 40.8 -73.9 22 #> 3 2013 1 1 5 JFK MIA N619AA AA John F… 40.6 -73.8 13 #> 4 2013 1 1 5 JFK BQN N804JB B6 John F… 40.6 -73.8 13 #> 5 2013 1 1 6 LGA ATL N668DN DL La Gua… 40.8 -73.9 22 #> 6 2013 1 1 5 EWR ORD N39463 UA Newark… 40.7 -74.2 18 #> # … with 336,770 more rows, and 3 more variables: tz <dbl>, dst <chr>, #> # tzone <chr>
13.4.6 Esercizi
-
Calcola il ritardo medio per destinazione, poi unisciti al data frame
airportin modo da poter mostrare la distribuzione spaziale dei ritardi. Ecco un modo semplice per disegnare una mappa degli Stati Uniti:airports %>% semi_join(flights, c("faa" = "dest")) %>% ggplot(aes(lon, lat)) + borders("state") + geom_point() + coord_quickmap()(Non preoccupatevi se non capite cosa fa
semi_join()— lo imparerete imparerete dopo).Potreste voler usare la
dimensioneo ilcoloredei punti per visualizzare il ritardo medio per ogni aeroporto. Aggiungi la posizione dell’origine e della destinazione (cioè la
late lalon) aflights.Esiste una relazione tra l’età di un aereo e i suoi ritardi?
Quali condizioni meteorologiche rendono più probabile un ritardo?
Cosa è successo il 13 giugno 2013? Visualizza lo schema spaziale dei ritardi, e poi usa Google per fare un riferimento incrociato con le condizionir.
13.4.7 Altre implementazioni
base::merge() può eseguire tutti e quattro i tipi di mutating join:
| dplyr | merge |
|---|---|
inner_join(x, y) |
merge(x, y) |
left_join(x, y) |
merge(x, y, all.x = TRUE) |
right_join(x, y) |
merge(x, y, all.y = TRUE), |
full_join(x, y) |
merge(x, y, all.x = TRUE, all.y = TRUE) |
Il vantaggio dei verbi specifici di dplyr è che trasmettono più chiaramente l’intento del vostro codice: la differenza tra i join è davvero importante ma nascosta negli argomenti di merge(). I join di dplyr sono considerevolmente più veloci e non incasinano l’ordine delle righe.
SQL è l’ispirazione per le convenzioni di dplyr, quindi la traduzione è semplice:
| dplyr | SQL |
|---|---|
inner_join(x, y, by = "z") |
SELECT * FROM x INNER JOIN y USING (z) |
left_join(x, y, by = "z") |
SELECT * FROM x LEFT OUTER JOIN y USING (z) |
right_join(x, y, by = "z") |
SELECT * FROM x RIGHT OUTER JOIN y USING (z) |
full_join(x, y, by = "z") |
SELECT * FROM x FULL OUTER JOIN y USING (z) |
Si noti che “INNER” e “OUTER” sono opzionali, e spesso omessi.
Unire diverse variabili tra le tabelle, per esempio inner_join(x, y, by = c("a" = "b")) usa una sintassi leggermente diversa in SQL: SELECT * FROM x INNER JOIN y ON x.a = y.b. Come suggerisce questa sintassi, SQL supporta una gamma più ampia di tipi di join rispetto a dplyr perché è possibile collegare le tabelle usando vincoli diversi dall’uguaglianza (a volte chiamati non-equijoin).
13.5 Filtering joins
Le filtering joins fanno corrispondere le osservazioni allo stesso modo delle mutating joins, ma influenzano le osservazioni, non le variabili. Ne esistono due tipi:
-
semi_join(x, y)tiene tutte le osservazioni inxche hanno una corrispondenza iny. -
anti_join(x, y)drops tutte le osservazioni inxche hanno una corrispondenza iny.
Le semi-join sono utili per far corrispondere tabelle di riepilogo filtrate alle righe originali. Per esempio, immaginate di aver trovato le prime dieci destinazioni più popolari:
top_dest <- flights %>%
count(dest, sort = TRUE) %>%
head(10)
top_dest
#> # A tibble: 10 × 2
#> dest n
#> <chr> <int>
#> 1 ORD 17283
#> 2 ATL 17215
#> 3 LAX 16174
#> 4 BOS 15508
#> 5 MCO 14082
#> 6 CLT 14064
#> # … with 4 more rowsOra vuoi trovare ogni volo che è andato a una di queste destinazioni. Potresti costruire tu stesso un filtro:
flights %>%
filter(dest %in% top_dest$dest)
#> # A tibble: 141,145 × 19
#> year month day dep_time sched_dep…¹ dep_d…² arr_t…³ sched…⁴ arr_d…⁵ carrier
#> <int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr>
#> 1 2013 1 1 542 540 2 923 850 33 AA
#> 2 2013 1 1 554 600 -6 812 837 -25 DL
#> 3 2013 1 1 554 558 -4 740 728 12 UA
#> 4 2013 1 1 555 600 -5 913 854 19 B6
#> 5 2013 1 1 557 600 -3 838 846 -8 B6
#> 6 2013 1 1 558 600 -2 753 745 8 AA
#> # … with 141,139 more rows, 9 more variables: flight <int>, tailnum <chr>,
#> # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
#> # minute <dbl>, time_hour <dttm>, and abbreviated variable names
#> # ¹sched_dep_time, ²dep_delay, ³arr_time, ⁴sched_arr_time, ⁵arr_delayMa è difficile estendere questo approccio a più variabili. Per esempio, immagina di aver trovato i 10 giorni con i più alti ritardi medi. Come costruireste la dichiarazione del filtro che usa year, month e day per abbinarlo a flight?
Invece puoi usare una semi-join, che collega le due tabelle come una mutating join, ma invece di aggiungere nuove colonne, mantiene solo le righe in x che hanno una corrispondenza in y:
flights %>%
semi_join(top_dest)
#> Joining with `by = join_by(dest)`
#> # A tibble: 141,145 × 19
#> year month day dep_time sched_dep…¹ dep_d…² arr_t…³ sched…⁴ arr_d…⁵ carrier
#> <int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr>
#> 1 2013 1 1 542 540 2 923 850 33 AA
#> 2 2013 1 1 554 600 -6 812 837 -25 DL
#> 3 2013 1 1 554 558 -4 740 728 12 UA
#> 4 2013 1 1 555 600 -5 913 854 19 B6
#> 5 2013 1 1 557 600 -3 838 846 -8 B6
#> 6 2013 1 1 558 600 -2 753 745 8 AA
#> # … with 141,139 more rows, 9 more variables: flight <int>, tailnum <chr>,
#> # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
#> # minute <dbl>, time_hour <dttm>, and abbreviated variable names
#> # ¹sched_dep_time, ²dep_delay, ³arr_time, ⁴sched_arr_time, ⁵arr_delayGraficamente, una semi-unione appare così:
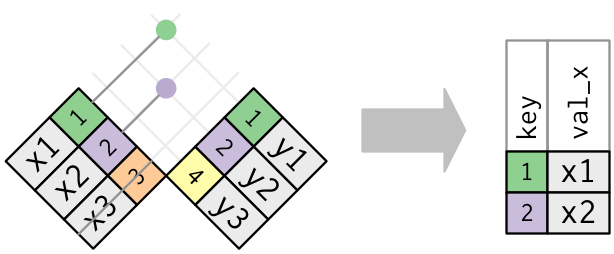
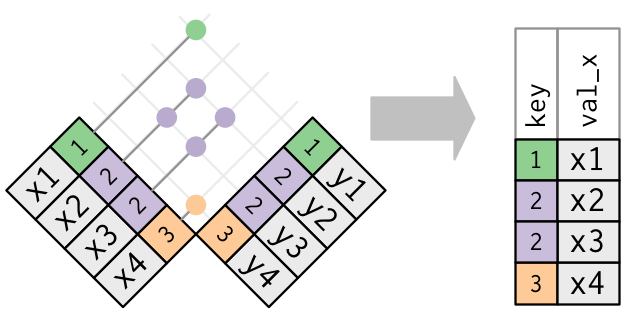
Solo l’esistenza di una corrispondenza è importante; non ha importanza quale osservazione viene abbinata. Questo significa che i filtering joins non duplicano mai le righe come fanno i mutating joins:
L’inverso di una semi-join è un anti-join. Un anti-join mantiene le righe che non hanno una corrispondenza:
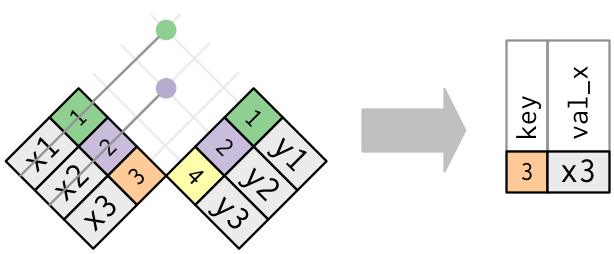
Gli anti-join sono utili per diagnosticare le mancate corrispondenze. Per esempio, quando si collegano flights e planes, si potrebbe essere interessati a sapere che ci sono molti flights che non hanno una corrispondenza in planes:
flights %>%
anti_join(planes, by = "tailnum") %>%
count(tailnum, sort = TRUE)
#> # A tibble: 722 × 2
#> tailnum n
#> <chr> <int>
#> 1 <NA> 2512
#> 2 N725MQ 575
#> 3 N722MQ 513
#> 4 N723MQ 507
#> 5 N713MQ 483
#> 6 N735MQ 396
#> # … with 716 more rows13.5.1 Esercizi
Cosa significa che un volo ha un
tailnummancante? Cosa hanno in comune i numeri di coda che non hanno un record corrispondente inplaneshanno in comune? (Suggerimento: una variabile spiega il ~90% dei problemi).Filtra i voli per mostrare solo i voli con aerei che hanno volato almeno 100 voli.
Combina
fueleconomy::vehiclesefueleconomy::commonper trovare solo i record per i modelli più comuni.Trova le 48 ore (nel corso dell’intero anno) che hanno i peggiori ritardi. Fai un riferimento incrociato con i dati
weather. Puoi vedere qualche modelli?-
Cosa ti dice
anti_join(flights, airports, by = c("dest" = "faa"))?- Che cosa ti dice
anti_join(airports, flights, by = c("faa" = "dest"))?
- Che cosa ti dice
Ci si potrebbe aspettare che ci sia una relazione implicita tra aereo e compagnia aerea, perché ogni aereo è pilotato da una sola compagnia aerea. Confermate o rifiutare questa ipotesi usando gli strumenti che hai imparato sopra.
13.6 Problemi di join
I dati con cui avete lavorato in questo capitolo sono stati puliti in modo che abbiate meno problemi possibili. E’ improbabile che i vostri dati siano così belli, quindi ci sono alcune cose che dovreste fare con i vostri dati per far sì che le vostre unioni vadano lisce.
-
Iniziate identificando le variabili che formano la chiave primaria in ogni tabella. Di solito dovreste farlo basandovi sulla vostra comprensione dei dati, non empiricamente cercando una combinazione di variabili che dia un identificatore unico. Se cercate solo le variabili senza pensare a al loro significato, potreste essere (dis)fortunati e trovare una combinazione che è unica nei vostri dati attuali, ma la relazione potrebbe non essere vera in generale.
Per esempio, l’altitudine e la longitudine identificano in modo unico ogni aeroporto, ma non sono buoni identificatori!
Controllare che nessuna delle variabili della chiave primaria sia mancante. Se un valore è mancante allora non può identificare un’osservazione!
-
Controlla che le tue chiavi esterne corrispondano alle chiavi primarie di un’altra tabella. Il modo migliore per farlo è con un
anti_join(). È comune che le chiavi non corrispondano a causa di errori nell’inserimento dei dati. Correggere questi errori è spesso un sacco di lavoro.Se avete delle chiavi mancanti, dovrete essere attenti all’uso l’uso delle unioni interne rispetto a quelle esterne, valutando attentamente se se volete eliminare le righe che non hanno una corrispondenza.
Siate consapevoli che controllare semplicemente il numero di righe prima e dopo l’unione non è sufficiente ad assicurare che la vostra unione sia andata bene. Se hai un join interno con chiavi duplicate in entrambe le tabelle, potresti essere sfortunato perché il numero di righe eliminate potrebbe essere esattamente uguale al numero di righe duplicate!
13.7 Operazioni di set
L’ultimo tipo di verbo di due tabelle sono le operazioni di set. Generalmente sono quelle che uso meno frequentemente, ma sono occasionalmente utili quando si vuole spezzare un singolo filtro complesso in pezzi più semplici. Tutte queste operazioni lavorano con una riga completa, confrontando i valori di ogni variabile. Queste si aspettano che gli input x e y abbiano le stesse variabili, e trattano le osservazioni come insiemi:
-
intersect(x, y): restituisce solo le osservazioni sia inxche iny. -
union(x, y): restituisce osservazioni uniche inxey. -
setdiff(x, y): restituisce le osservazioni inx, ma non iny.
Dati questi semplici dati:
Le quattro possibilità sono:
intersect(df1, df2)
#> # A tibble: 1 × 2
#> x y
#> <dbl> <dbl>
#> 1 1 1
# Notate che otteniamo 3 righe, non 4
union(df1, df2)
#> # A tibble: 3 × 2
#> x y
#> <dbl> <dbl>
#> 1 1 1
#> 2 2 1
#> 3 1 2
setdiff(df1, df2)
#> # A tibble: 1 × 2
#> x y
#> <dbl> <dbl>
#> 1 2 1
setdiff(df2, df1)
#> # A tibble: 1 × 2
#> x y
#> <dbl> <dbl>
#> 1 1 2