1 Introduzione
La scienza dei dati (data science) è una disciplina eccitante che permette di trasformare i dati grezzi in comprensione, intuizione e conoscenza. L’obiettivo di “R for Data Science” è di aiutarvi a imparare gli strumenti più importanti in R che vi permetteranno di fare data science. Dopo aver letto questo libro, avrete gli strumenti per affrontare un’ampia varietà di sfide, usando le parti migliori di R.
1.1 Cosa imparerai
La data science è una disciplina enorme, e non c’è modo di padroneggiarla leggendo un solo libro. L’obiettivo di questo libro è di darvi una solida base negli strumenti più importanti. Il nostro modello degli strumenti necessari in un tipico progetto di data science assomiglia a questo:
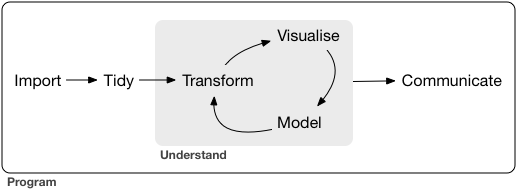
Per prima cosa devi importare i tuoi dati in R. Questo tipicamente significa che prendi i dati memorizzati in un file, database, o interfaccia di programmazione per applicazioni web (API, Application Programming Interface), e li carichi in un data frame in R. Se non puoi importare i tuoi dati in R, non puoi fare data science su di essi!
Una volta che hai importato i tuoi dati, è una buona idea metterli in ordine ( tidy ). Riordinare i tuoi dati significa memorizzarli in una forma coerente che corrisponda alla semantica del dataset con il modo in cui è memorizzato. In breve, quando i tuoi dati sono ordinati, ogni colonna è una variabile e ogni riga è un’osservazione. I dati ordinati sono importanti perché la struttura coerente vi permette di concentrare la tua attenzione alle domande sui dati, senza lottare per mettere i dati nella forma giusta per diverse funzioni.
Una volta che si hanno dati ordinati, un primo passo comune è quello di trasformarli( transform ). La trasformazione include il concentrarsi sulle osservazioni di interesse (come tutte le persone in una città, o tutti i dati dell’ultimo anno), la creazione di nuove variabili che sono funzioni di variabili esistenti (come calcolare la velocità dalla distanza e dal tempo), e il calcolo di una serie di statistiche riassuntive (come i conteggi o le medie). Insieme, il riordino e la trasformazione sono chiamati “lotta” ( wrangling ), perché ottenere che i tuoi dati abbiano una forma che sia naturale per lavorarci spesso sembra una lotta!
Una volta che hai dati ordinati con le variabili di cui hai bisogno, ci sono due motori principali di generazione della conoscenza: visualizzazione e modellazione. Questi hanno punti di forza e di debolezza complementari, quindi ogni vera analisi itererà tra loro molte volte.
La visualizzazione ( visualisation ) è un’attività fondamentalmente umana. Una buona visualizzazione ti mostrerà cose che non ti aspettavi, o solleverà nuove domande sui dati. Una buona visualizzazione potrebbe anche suggerirti che ti stavi facendo la domanda sbagliata, o che hai bisogno di raccogliere dati diversi. Le visualizzazioni possono sorprendere, ma non sono particolarmente adatte perché richiedono un umano che le interpreti.
I modelli ( models ) sono strumenti complementari alla visualizzazione. Una volta che hai reso le tue domande sufficientemente precise, puoi usare un modello per rispondere. I modelli sono uno strumento fondamentalmente matematico o computazionale, quindi generalmente sono ben scalabili. Anche quando non lo fanno, di solito è più economico comprare più computer che comprare più cervelli! Ma ogni modello fa delle ipotesi, e per sua natura un modello non può mettere in discussione le proprie ipotesi. Ciò significa che un modello non può fondamentalmente sorprenderti.
L’ultimo passo della scienza dei dati è la comunicazione ( communication ), una parte assolutamente critica di qualsiasi progetto di analisi di dati. Non importa quanto bene i tuoi modelli e la visualizzazione ti abbiano portato a capire i dati se non puoi anche comunicare i tuoi risultati ad altri.
Attorno a tutti questi strumenti c’è la programmazione ( programming ). La programmazione è uno strumento trasversale che si usa in ogni parte del progetto. Non c’è bisogno di essere un programmatore esperto per essere uno scienziato dei dati, ma imparare di più sulla programmazione ripaga perché diventare un programmatore migliore permette di automatizzare compiti comuni e risolvere nuovi problemi con maggiore facilità.
Userai questi strumenti in ogni progetto di data science, ma per la maggior parte dei progetti non sono sufficienti. C’è una regola approssimativa 80-20 in gioco; potete affrontare circa l’80% di ogni progetto usando gli strumenti che imparerete in questo libro, ma avrete bisogno di altri strumenti per affrontare il restante 20%. In tutto questo libro ti indicheremo le risorse dove puoi imparare di più.
1.2 Come è organizzato questo libro
La precedente descrizione degli strumenti della data science è organizzata all’incirca secondo l’ordine in cui li userai in un’analisi (anche se naturalmente li ripasserai più volte). Nella nostra esperienza, tuttavia, questo non è il modo migliore per impararli:
Iniziare con l’inserimento e il riordino dei dati è sub-ottimale perché l’80% del tempo è di routine e noioso, e il restante 20% del tempo è strano e frustrante. Questo è un brutto posto per iniziare a imparare una nuova materia! Invece, inizieremo con la visualizzazione e la trasformazione di dati che sono già stati importati e riordinati. In questo modo, quando importerai e riordinerai i tuoi dati, la tua motivazione rimarrà alta perché saprai che la frustrazione inziale ne varrà la pena.
Alcuni argomenti sono spiegati meglio con altri strumenti. Per esempio, crediamo che sia più facile capire come funzionano i modelli se si conoscono già visualizzazione, dati ordinati e programmazione.
Gli strumenti di programmazione non sono necessariamente interessanti di per sé, ma ti permettono di affrontare problemi molto più impegnativi. Noi ti daremo una selezione di strumenti di programmazione a metà del libro, e poi vedrai come possono combinarsi con gli strumenti di data science per affrontare interessanti problemi di modellazione.
All’interno di ogni capitolo, cerchiamo di attenerci a uno schema simile: iniziamo con alcuni esempi motivanti in modo che tu possa vedere il quadro generale, e poi ci immergiamo nei dettagli. Ogni sezione del libro è accompagnata da esercizi per aiutarti a mettere in pratica ciò che hai imparato. Anche se si è tentati di saltare gli esercizi, non c’è modo migliore per imparare che fare pratica su problemi reali.
1.3 Cosa non imparerai
Ci sono alcuni argomenti importanti che questo libro non tratta. Crediamo che sia importante rimanere spietatamente concentrati sull’essenziale in modo da poter essere operativi il più velocemente possibile. Ciò significa che questo libro non può coprire tutti gli argomenti importanti.
1.3.1 Big data
Questo libro si concentra orgogliosamente su piccoli set di dati che stanno nella memoria di un normale PC. Questo è il posto giusto per iniziare perché non si possono affrontare i big data se non si ha esperienza con i piccoli dati. Gli strumenti che imparerai in questo libro saranno utili a gestire facilmente centinaia di megabyte di dati, e con un po’ di attenzione potrai usarli per lavorare con 1-2 Gb di dati. Se lavori abitualmente con dati più grandi (10-100 Gb, diciamo), dovresti imparare di più su data.table. Questo libro non insegna data.table perché ha un’interfaccia molto concisa che lo rende più difficile da imparare poiché offre meno spunti linguistici. Ma se stai lavorando con grandi dati, il guadagno in termini di prestazioni vale lo sforzo extra richiesto per impararlo.
Se i tuoi dati sono ancora più grandi, valuta attentamente se il tuo problema di big data possa essere in realtà un problema di small data sotto mentite spoglie. Mentre i dati completi potrebbero essere grandi, spesso i dati necessari per rispondere a una domanda specifica sono piccoli. Potresti essere in grado di trovare un sottoinsieme, un sottocampione o un riassunto che si adatti alla memoria del tuo PC e che ti permetta comunque di rispondere alla domanda che ti interessa. La sfida in questo caso è trovare i piccoli dati giusti, il che spesso richiede un sacco di prove.
Un’altra possibilità è che il tuo problema di grandi dati sia in realtà un gran numero di problemi di piccoli dati. Ogni singolo problema potrebbe adattarsi alla memoria, ma ne hai milioni. Per esempio, potresti voler adattare un modello a ogni persona nel tuo set di dati. Questo sarebbe banale se tu avessi solo 10 o 100 persone, ma invece ne hai un milione. Fortunatamente ogni problema è indipendente dagli altri (una configurazione che a volte viene chiamata “imbarazzantemente parallela” ( embarrassingly parallel )), quindi hai solo bisogno di un sistema (come Hadoop o Spark) che ti permetta di inviare diversi set di dati a diversi computer per l’elaborazione. Una volta che hai capito come rispondere alla domanda per un singolo sottoinsieme usando gli strumenti descritti in questo libro, impari nuovi strumenti come sparklyr, rhipe e ddr per risolverla per l’intero set di dati.
1.3.2 Python, Julia e amici
In questo libro, non imparerai nulla su Python, Julia, o qualsiasi altro linguaggio di programmazione utile per la scienza dei dati. Questo non perché pensiamo che questi strumenti siano terribili. Non lo sono! E in pratica, la maggior parte dei team di data science usa un mix di linguaggi, spesso almeno R e Python.
Tuttavia, crediamo fortemente che sia meglio padroneggiare uno strumento alla volta. Migliorerai più velocemente se ti immergerai in profondità, piuttosto che sparpagliarti su molti argomenti. Questo non significa che dovrai sapere solo una cosa, solo che in genere imparerai più velocemente se ti atterrai a una cosa alla volta. Dovresti sforzarti di imparare nuove cose durante la tua carriera, ma assicurati che la tua comprensione sia solida prima di passare alla prossima cosa interessante.
Pensiamo che R sia un ottimo posto per iniziare il tuo viaggio nella scienza dei dati perché è un ambiente progettato da zero per supportarela. R non è solo un linguaggio di programmazione, ma è anche un ambiente interattivo. Per supportare l’interazione, R è un linguaggio molto più flessibile di molti dei suoi colleghi. Questa flessibilità ha i suoi lati negativi, ma il grande vantaggio è quanto sia facile evolvere grammatiche su misura per parti specifiche del processo di data science. Questi mini linguaggi ti aiutano a pensare ai problemi come uno scienziato dei dati, mentre supportano un’interazione fluida tra il tuo cervello e il computer.
1.3.3 Dati non rettangolari
Questo libro si concentra esclusivamente su dati rettangolari: collezioni di valori che sono ciascuno associato a una variabile e a un’osservazione. Ci sono molti insiemi di dati che non rientrano naturalmente in questo paradigma, comprese le immagini, i suoni, gli alberi e il testo. Ma i data frame rettangolari sono estremamente comuni nella scienza e nell’industria, e noi crediamo che siano un ottimo punto di partenza per il tuo viaggio.
1.3.4 Conferma delle ipotesi
È possibile dividere l’analisi dei dati in due campi: la generazione di ipotesi e la conferma di ipotesi (a volte chiamata analisi confermativa). Il focus di questo libro è apertamente sulla generazione di ipotesi, o esplorazione dei dati. Qui guarderai profondamente i dati e, in combinazione con la tua conoscenza della materia, genererai molte ipotesi interessanti per aiutare a spiegare perché i dati si comportino in quel modo. Valuterai le ipotesi in modo informale, usando il tuo scetticismo per sfidare i dati in vari modi.
Il complemento della generazione di ipotesi è la conferma delle ipotesi. La conferma delle ipotesi è difficile per due motivi:
Ha bisogno di un modello matematico preciso per generare previsioni falsificabili. Questo spesso richiede una notevole sofisticazione statistica.
Si può usare un’osservazione solo una volta per confermare un’ipotesi. Non appena la si usa più di una volta si torna a fare analisi esplorative. Questo significa che per fare la conferma dell’ipotesi hai bisogno di “pre-registrare” (scrivere in anticipo) il tuo piano di analisi, e non deviare da esso neanche dopo aver visto i dati. Parleremo un po’ di alcune strategie che puoi usare per rendere questo più facile in modelling.
È comune pensare alla modellazione ( modelling ) come uno strumento per la conferma delle ipotesi, e alla visualizzazione come uno strumento per la generazione di ipotesi. Ma questa è una falsa dicotomia: i modelli sono spesso usati per l’esplorazione, e con un po’ di attenzione si può usare la visualizzazione per la conferma. La differenza chiave è quanto spesso si guarda ogni osservazione: se si guarda solo una volta, è conferma; se si guarda più di una volta, è esplorazione.
1.4 Prerequisiti
Abbiamo fatto alcune supposizioni su ciò che già sai per ottenere il massimo da questo libro. Dovresti essere generalmente alfabetizzato dal punto di vista numerico, ed è utile tu abbia già qualche esperienza di programmazione. Se non hai mai programmato prima, potresti trovare Hands on Programming with R di Garrett come utile complemento a questo libro.
Ci sono quattro cose di cui avrai bisogno per eseguire il codice in questo libro: R, RStudio, una collezione di pacchetti di R chiamata tidyverse, e una manciata di altri pacchetti. I pacchetti sono le unità fondamentali del codice R riproducibile. Includono funzioni riutilizzabili, la documentazione che descrive come usarle, e dati di esempio.
1.4.1 RStudio
RStudio è un ambiente di sviluppo integrato, o IDE (Integrated Development Environment), per la programmazione in R. Scaricalo e installalo da http://www.rstudio.com/download. RStudio viene aggiornato un paio di volte all’anno. Quando una nuova versione è disponibile, RStudio te lo farà sapere. È una buona idea aggiornare regolarmente in modo da poter trarre vantaggio dalle ultime e più grandi caratteristiche. Per questo libro, assicuratevi di avere almeno RStudio 1.0.0.
Quando avvierai RStudio, vedrai due regioni chiave nell’interfaccia:
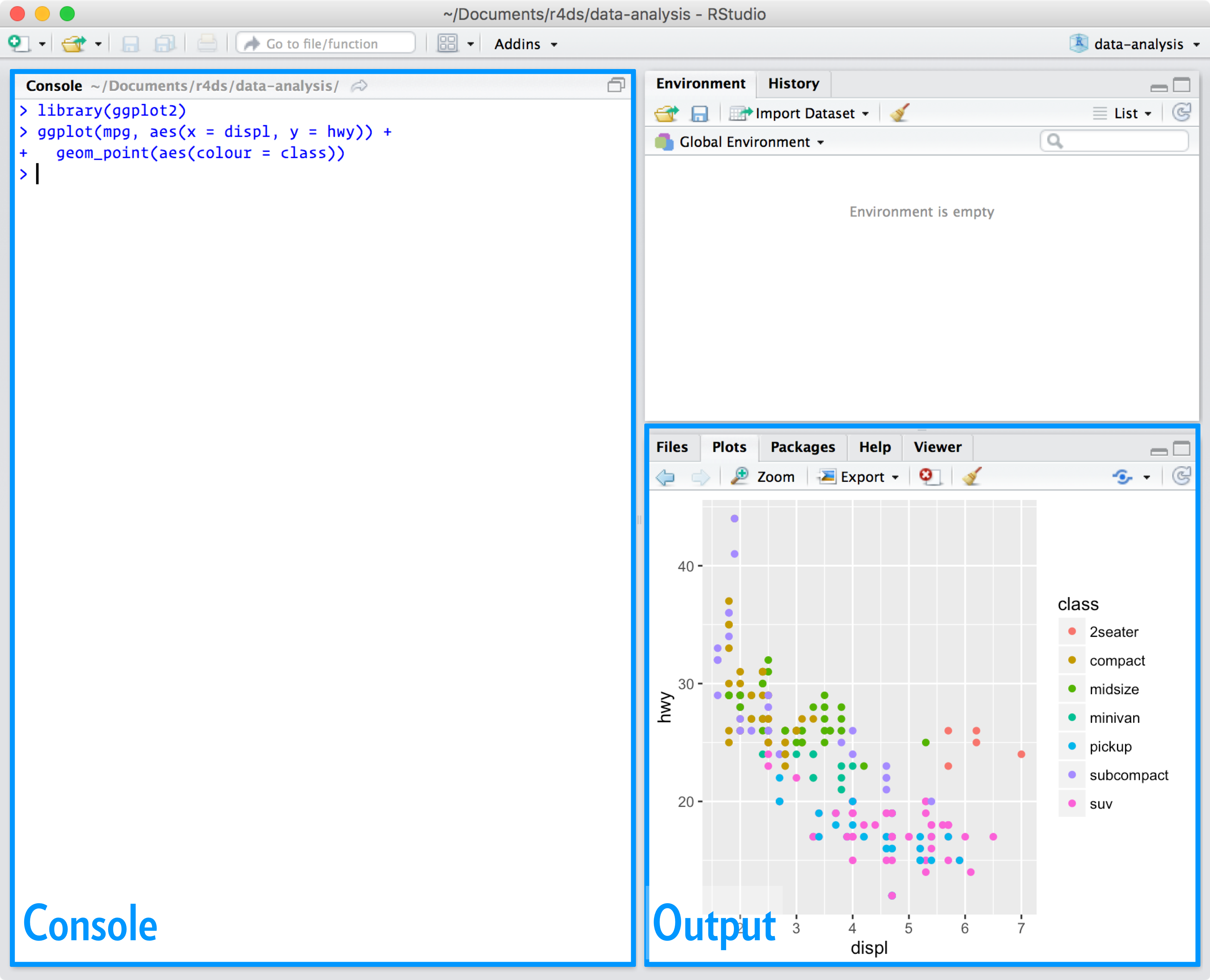
Per ora, tutto quello che devi sapere è che digiti il codice R nel pannello della console e premi invio per eseguirlo. Imparerai di più andando avanti!
1.4.2 Il tidyverse
Avrai anche bisogno di installare alcuni pacchetti R. Un pacchetto (‘package’) di R è una collezione di funzioni, dati e documentazione che estende le capacità di R di base. L’uso dei pacchetti è la chiave per un uso efficace di R. La maggior parte dei pacchetti che imparerai in questo libro fanno parte del cosiddetto tidyverse. I pacchetti del tidyverse condividono una comune filosofia dei dati e della programmazione in R, e sono progettati per lavorare insieme in modo naturale.
Puoi installare l’intero tidyverse con una sola linea di codice:
install.packages("tidyverse")Sul tuo computer, digita questa linea di codice nella console, e poi premi invio per eseguirla. R scaricherà i pacchetti da CRAN e li installerà sul tuo computer. Se hai problemi nell’installazione, assicurati di avere attiva la connessione a internet e che https://cloud.r-project.org/ non sia bloccato da firewall o proxy.
Non sarai in grado di usare le funzioni, gli oggetti e i file di aiuto di un pacchetto finché non lo caricherai con library(). Una volta che hai installato un pacchetto, puoi caricarlo con la funzione library():
library(tidyverse)
#> ── Attaching packages ─────────────────────────────────────── tidyverse 1.3.2 ──
#> ✔ ggplot2 3.4.1 ✔ purrr 1.0.1
#> ✔ tibble 3.1.8 ✔ dplyr 1.1.0
#> ✔ tidyr 1.3.0 ✔ stringr 1.5.0
#> ✔ readr 2.1.4 ✔ forcats 1.0.0
#> ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
#> ✖ dplyr::filter() masks stats::filter()
#> ✖ dplyr::lag() masks stats::lag()Questo ti dice che tidyverse sta caricando i pacchetti ggplot2, tibble, tidyr, readr, purrr e dplyr. Questi sono considerati il core (‘nucleo’) del tidyverse perché li userai in quasi tutte le analisi.
I pacchetti del tidyverse cambiano abbastanza frequentemente. Puoi vedere se sono disponibili aggiornamenti, e opzionalmente installarli, eseguendo tidyverse_update().
1.4.3 Altri pacchetti
Ci sono molti altri eccellenti pacchetti che non fanno parte del tidyverse, perché risolvono problemi in un dominio diverso, o sono progettati con un diverso insieme di principi di base. Questo non li rende migliori o peggiori, solo diversi. In altre parole, il complemento al tidyverse non è il messyverse3, ma molti altri universi di pacchetti interconnessi. Man mano che affronterai più progetti di scienza dei dati con R, imparerai nuovi pacchetti e nuovi modi di pensare ai dati.
In questo libro useremo tre pacchetti di dati al di fuori del tidyverse:
install.packages(c("nycflights13", "gapminder", "Lahman"))Questi pacchetti forniscono dati sui voli aerei, sullo sviluppo mondiale e sul baseball che useremo per illustrare le idee chiave della scienza dei dati.
1.5 Eseguire il codice R
La sezione precedente ti ha mostrato un paio di esempi di esecuzione del codice R. Il codice nel libro assomiglia a questo:
1 + 2
#> [1] 3Se esegui lo stesso codice nella tua console locale, apparirà così:
> 1 + 2
[1] 3Ci sono due differenze principali. Nella tua console, digiti dopo il >, chiamato prompt; nel libro non mostriamo il prompt. Nel libro, l’output è commentato con #>>; nella tua console appare direttamente dopo il tuo codice. Queste due differenze sono utili se stai lavorando con una versione elettronica del libro, e puoi facilmente copiare il codice dal libro alla console.
In tutto il libro usiamo un insieme coerente di convenzioni per riferirci al codice:
Le funzioni sono in un carattere di codice e seguite da parentesi, come
sum(), omean().Altri oggetti R (come dati o argomenti di funzioni) sono in un font di codice, senza parentesi, come
flightsox.Se vogliamo rendere chiaro da quale pacchetto proviene un oggetto, useremo il nome del pacchetto seguito da due punti, come
dplyr::mutate(), onycflights13::flights. Anche questo è un codice R valido.
1.6 Ottenere aiuto e imparare di più
Questo libro non è un’isola; non c’è una singola risorsa che ti permetterà di padroneggiare R. Quando inizierai ad applicare le tecniche descritte in questo libro ai tuoi dati, troverai presto delle domande a cui non abbiamo risposto. Questa sezione descrive alcuni suggerimenti su come ottenere aiuto, e per aiutarti a continuare a imparare.
Se ci si blocca, si iniza con Google. Di solito l’aggiunta di “R” a una ricerca è sufficiente a limitarla ai soli risultati pertinenti: se la ricerca non è utile, spesso significa che non ci sono risultati specifici per R disponibili. Google è particolarmente utile per i messaggi di errore. Se ricevi un messaggio di errore e non hai idea di cosa significhi, prova a cercarlo su Google! È probabile che qualcun altro sia stato confuso da questo messaggio in passato, e ci sarà un aiuto da qualche parte sul web. (Se il messaggio di errore non è in italiano, esegui Sys.setenv(LANGUAGE = "it") e riesegui il codice; è più probabile trovare aiuto in italiano per messaggi di errore in italiano).
Se Google non aiuta, prova stackoverflow. Inizia a dedicare un po’ di tempo alla ricerca di una risposta esistente, includendo [R] per limitare la ricerca a domande e risposte che usano R. Se non trovi nulla di utile, prepara un esempio minimo riproducibile o reprex. Un buon reprex rende più facile per le altre persone aiutarti, e spesso risolverai il problema in autonomia nel corso della sua realizzazione.
Ci sono tre cose che dovresti includere per rendere il tuo esempio riproducibile: i pacchetti necessari, i dati e il codice.
I Pacchetti dovrebbero essere caricati all’inizio dello script, così è facile vedere di quali l’esempio ha bisogno. Questo è un buon momento per controllare che si stia usando l’ultima versione di ogni pacchetto; è possibile che tu abbia scoperto un bug che sia stato risolto da quando hai installato il pacchetto. Per i pacchetti nel tidyverse, il modo più semplice per controllare è eseguire
tidyverse_update().-
Il modo più semplice per includere dati in una domanda è usare
dput()per generare il codice R per ricrearlo. Per esempio, per ricreare il dataset `mtcars in R, esegui i seguenti passi:- Esegui
dput(mtcars)in R - Copia l’output
- Nel tuo script riproducibile, scrivi
mtcars <-e poi incolla.
Prova a trovare il più piccolo sottoinsieme dei tuoi dati che rivela ancora il problema.
- Esegui
-
Spendi un po’ di tempo per assicurarti che il tuo codice sia facile da leggere:
Assicurati di aver usato spazi e che i nomi delle tue variabili siano concisi, ma informativi.
Usa i commenti (testo preceduto da
#) per indicare dove sta il tuo problema.Fai del tuo meglio per rimuovere tutto ciò che non è collegato al problema.
Più corto e più facile è da capire è il tuo codice, e più facile sarà da correggere.
Finisci controllando che hai effettivamente fatto un esempio riproducibile iniziando una nuova sessione di R e copiando e incollando il tuo script.
Dovresti anche spendere un po’ di tempo per prepararti a risolvere i problemi prima che si presentino. Investire un po’ di tempo per imparare R ogni giorno ti ripagherà ampiamente nel lungo periodo. Un modo è quello di seguire quello che Hadley, Garrett, e tutti gli altri a RStudio stanno facendo sul RStudio blog. Qui è dove pubblichiamo annunci su nuovi pacchetti, nuove caratteristiche dell’IDE, e corsi di persona. Potresti anche seguire Hadley (@hadleywickham) o Garrett (@statgarrett) su Twitter, o seguire @rstudiotips per essere aggiornati sulle nuove funzionalità dell’IDE.
Per stare al passo con la comunità R più in generale, ti consigliamo di leggere http://www.r-bloggers.com: aggrega oltre 500 blog su R da tutto il mondo. Se sei un utente attivo di Twitter, segui l’hashtag (#rstats). Twitter è uno degli strumenti chiave che Hadley usa per stare al passo con i nuovi sviluppi della comunità.
1.7 Ringraziamenti
Questo libro non è solo il prodotto di Hadley e Garrett, ma è il risultato di molte conversazioni (di persona e online) che abbiamo avuto con molte persone nella comunità R. Ci sono alcune persone che vorremmo ringraziare in particolare, perché hanno passato molte ore a rispondere alle nostre stupide domande e ci hanno aiutato a pensare meglio alla scienza dei dati:
Jenny Bryan e Lionel Henry per molte utili discussioni sul lavoro con liste e colonne di liste.
I tre capitoli sul workflow (‘flusso di lavoro’) sono stati adattati (con permesso) da http://stat545.com/block002_hello-r-workspace-wd-project.html da Jenny Bryan.
Genevera Allen per le discussioni sui modelli, la modellazione, la prospettiva di apprendimento statistico, e la differenza tra generazione di ipotesi e conferma delle ipotesi.
Yihui Xie per il suo lavoro sul pacchetto bookdown e per aver risposto instancabilmente alle nostre richieste di funzionalità.
Bill Behrman per la sua attenta lettura dell’intero libro, e per averlo provato con la sua classe di data science a Stanford.
La comunità di twitter di #rstats che ha rivisto tutte le bozze dei capitoli e ha fornito tonnellate di feedback utili.
Tal Galili per aver migliorato il suo pacchetto dendextend per supportare una sezione sul clustering che non è stata inserita nella bozza finale.
Questo libro è stato scritto in modo aperto, e molte persone hanno contribuito con pull request per risolvere problemi minori. Un ringraziamento speciale va a tutti coloro che hanno contribuito tramite GitHub:
Grazie a tutti i collaboratori in ordine alfabetico: A. s, Abhinav Singh, Ahmed ElGabbas, Ajay Deonarine, @AlanFeder, Albert Y. Kim, @Alex, Andrea Gilardi, Andrew Landgraf, Angela Li, Azza Ahmed, Ben Herbertson, Ben Marwick, Ben Steinberg, Benjamin Yeh, Bianca Peterson, Bill Behrman, @BirgerNi, Brandon Greenwell, Brent Brewington, Brett Klamer, Brian G. Barkley, Charlotte Wickham, Christian G. Warden, Christian Heinrich, Christian Mongeau, Colin Gillespie, Cooper Morris, Curtis Alexander, @DSGeoff, Daniel Gromer, David Clark, David Rubinger, Derwin McGeary, Devin Pastoor, Dirk Eddelbuettel, Dylan Cashman, Earl Brown, Edwin Thoen, Eric Watt, Erik Erhardt, Etienne B. Racine, Everett Robinson, Flemming Villalona, Floris Vanderhaeghe, Garrick Aden-Buie, George Wang, Gregory Jefferis, Gustav W Delius, Hao Chen, Hengni Cai, Hiroaki Yutani, Hojjat Salmasian, Ian Lyttle, Ian Sealy, Ivan Krukov, Jacek Kolacz, Jacob Kaplan, Jakub Nowosad, Jazz Weisman, Jeff Boichuk, Jeffrey Arnold, Jen Ren, Jennifer (Jenny) Bryan, Jeroen Janssens, Jim Hester, Joanne Jang, Johannes Gruber, John Blischak, John D. Storey, John Sears, Jon Calder, @Jonas, Jonathan Page, Jose Roberto Ayala Solares, Josh Goldberg, Julia Stewart Lowndes, Julian During, Justinas Petuchovas, Kara Woo, Kara de la Marck, Katrin Leinweber, Kenny Darrell, Kirill Müller, Kirill Sevastyanenko, Kunal Marwaha, @KyleHumphrey, Lawrence Wu, Luke Smith, Luke W Johnston, @MJMarshall, Mara Averick, Maria Paula Caldas, Mark Beveridge, Matt Herman, @MattWittbrodt, Matthew Hendrickson, Matthew Sedaghatfar, Mauro Lepore, Michael Henry, Mine Cetinkaya-Rundel, Mustafa Ascha, Nelson Areal, Nicholas Tierney, Nick Clark, Nina Munkholt Jakobsen, Nirmal Patel, Nischal Shrestha, Noah Landesberg, @OaCantona, Pablo E, Patrick Kennedy, @Paul, Peter Hurford, Rademeyer Vermaak, Radu Grosu, Ranae Dietzel, Riva Quiroga, Rob Tenorio, Robert Schuessler, Robin Gertenbach, Rohan Alexander, @RomeroBarata, S’busiso Mkhondwane, @Saghir, Sam Firke, Seamus McKinsey, Sebastian Kraus, Shannon Ellis, @Sophiazj, Steve Mortimer, Stéphane Guillou, TJ Mahr, Tal Galili, Terence Teo, Thomas Klebel, Tim Waterhouse, Tom Prior, Ulrik Lyngs, Will Beasley, Yihui Xie, Yiming (Paul) Li, Yu Yu Aung, Zach Bogart, Zhuoer Dong, @a-rosenberg, adi pradhan, @andrewmacfarland, bahadir cankardes, @batpigandme, @behrman, @boardtc, @djbirke, @harrismcgehee, @jennybc, @jjchern, @jonathanflint, @juandering, @kaetschap, @kdpsingh, @koalabearski, @lindbrook, @nate-d-olson, @nattalides, @nickelas, @nwaff, @pete, @rlzijdeman, @robertchu03, @robinlovelace, @robinsones, @seamus-mckinsey, @seanpwilliams, @shoili, @sibusiso16, @spirgel, @svenski, @twgardner2, @yahwes, @zeal626, @蒋雨蒙.
1.8 Colophon
Una versione online (in inglese) di questo libro è disponibile su http://r4ds.had.co.nz. Continuerà a evolversi tra una ristampa e l’altra del libro fisico. Il sorgente del libro è disponibile su https://github.com/hadley/r4ds o su https://github.com/lucavd/r4ds_ita_1st_ed per l’edizione italiana. Il libro è costruito su https://bookdown.org che rende facile trasformare i file markdown di R in HTML, PDF ed EPUB.
Questo libro è stato costruito con:
sessioninfo::session_info(c("tidyverse"))
#> ─ Session info ───────────────────────────────────────────────────────────────
#> setting value
#> version R version 4.2.2 (2022-10-31)
#> os Ubuntu 22.04.1 LTS
#> system x86_64, linux-gnu
#> ui X11
#> language (EN)
#> collate C.UTF-8
#> ctype C.UTF-8
#> tz UTC
#> date 2023-02-17
#> pandoc 2.19.2 @ /usr/bin/ (via rmarkdown)
#>
#> ─ Packages ───────────────────────────────────────────────────────────────────
#> package * version date (UTC) lib source
#> askpass 1.1 2019-01-13 [1] CRAN (R 4.2.2)
#> assertthat 0.2.1 2019-03-21 [1] CRAN (R 4.2.2)
#> backports 1.4.1 2021-12-13 [1] CRAN (R 4.2.2)
#> base64enc 0.1-3 2015-07-28 [1] CRAN (R 4.2.2)
#> bit 4.0.5 2022-11-15 [1] CRAN (R 4.2.2)
#> bit64 4.0.5 2020-08-30 [1] CRAN (R 4.2.2)
#> blob 1.2.3 2022-04-10 [1] CRAN (R 4.2.2)
#> broom 1.0.3 2023-01-25 [1] CRAN (R 4.2.2)
#> bslib 0.4.2.9000 2023-02-17 [1] Github (rstudio/bslib@fe41d6d)
#> cachem 1.0.6 2021-08-19 [1] CRAN (R 4.2.2)
#> callr 3.7.3 2022-11-02 [1] CRAN (R 4.2.2)
#> cellranger 1.1.0 2016-07-27 [1] CRAN (R 4.2.2)
#> cli 3.6.0 2023-01-09 [1] CRAN (R 4.2.2)
#> clipr 0.8.0 2022-02-22 [1] CRAN (R 4.2.2)
#> colorspace 2.1-0 2023-01-23 [1] CRAN (R 4.2.2)
#> cpp11 0.4.3 2022-10-12 [1] CRAN (R 4.2.2)
#> crayon 1.5.2 2022-09-29 [1] CRAN (R 4.2.2)
#> curl 5.0.0 2023-01-12 [1] CRAN (R 4.2.2)
#> data.table 1.14.8 2023-02-17 [1] CRAN (R 4.2.2)
#> DBI 1.1.3 2022-06-18 [1] CRAN (R 4.2.2)
#> dbplyr 2.3.0 2023-01-16 [1] CRAN (R 4.2.2)
#> digest 0.6.31 2022-12-11 [1] CRAN (R 4.2.2)
#> dplyr * 1.1.0 2023-01-29 [1] CRAN (R 4.2.2)
#> dtplyr 1.2.2 2022-08-20 [1] CRAN (R 4.2.2)
#> ellipsis 0.3.2 2021-04-29 [1] CRAN (R 4.2.2)
#> evaluate 0.20 2023-01-17 [1] CRAN (R 4.2.2)
#> fansi 1.0.4 2023-01-22 [1] CRAN (R 4.2.2)
#> farver 2.1.1 2022-07-06 [1] CRAN (R 4.2.2)
#> fastmap 1.1.0 2021-01-25 [1] CRAN (R 4.2.2)
#> forcats * 1.0.0 2023-01-29 [1] CRAN (R 4.2.2)
#> fs 1.6.1 2023-02-06 [1] CRAN (R 4.2.2)
#> gargle 1.3.0 2023-01-30 [1] CRAN (R 4.2.2)
#> generics 0.1.3 2022-07-05 [1] CRAN (R 4.2.2)
#> ggplot2 * 3.4.1 2023-02-10 [1] CRAN (R 4.2.2)
#> glue 1.6.2 2022-02-24 [1] CRAN (R 4.2.2)
#> googledrive 2.0.0 2021-07-08 [1] CRAN (R 4.2.2)
#> googlesheets4 1.0.1 2022-08-13 [1] CRAN (R 4.2.2)
#> gtable 0.3.1 2022-09-01 [1] CRAN (R 4.2.2)
#> haven 2.5.1 2022-08-22 [1] CRAN (R 4.2.2)
#> highr 0.10 2022-12-22 [1] CRAN (R 4.2.2)
#> hms 1.1.2 2022-08-19 [1] CRAN (R 4.2.2)
#> htmltools 0.5.4 2022-12-07 [1] CRAN (R 4.2.2)
#> httr 1.4.4 2022-08-17 [1] CRAN (R 4.2.2)
#> ids 1.0.1 2017-05-31 [1] CRAN (R 4.2.2)
#> isoband 0.2.7 2022-12-20 [1] CRAN (R 4.2.2)
#> jquerylib 0.1.4 2021-04-26 [1] CRAN (R 4.2.2)
#> jsonlite 1.8.4 2022-12-06 [1] CRAN (R 4.2.2)
#> knitr 1.42 2023-01-25 [1] CRAN (R 4.2.2)
#> labeling 0.4.2 2020-10-20 [1] CRAN (R 4.2.2)
#> lattice 0.20-45 2021-09-22 [2] CRAN (R 4.2.2)
#> lifecycle 1.0.3 2022-10-07 [1] CRAN (R 4.2.2)
#> lubridate 1.9.2 2023-02-10 [1] CRAN (R 4.2.2)
#> magrittr 2.0.3 2022-03-30 [1] CRAN (R 4.2.2)
#> MASS 7.3-58.2 2023-01-23 [1] CRAN (R 4.2.2)
#> Matrix 1.5-3 2022-11-11 [1] CRAN (R 4.2.2)
#> memoise 2.0.1 2021-11-26 [1] CRAN (R 4.2.2)
#> mgcv 1.8-41 2022-10-21 [2] CRAN (R 4.2.2)
#> mime 0.12 2021-09-28 [1] CRAN (R 4.2.2)
#> modelr 0.1.10 2022-11-11 [1] CRAN (R 4.2.2)
#> munsell 0.5.0 2018-06-12 [1] CRAN (R 4.2.2)
#> nlme 3.1-162 2023-01-31 [1] CRAN (R 4.2.2)
#> openssl 2.0.5 2022-12-06 [1] CRAN (R 4.2.2)
#> pillar 1.8.1 2022-08-19 [1] CRAN (R 4.2.2)
#> pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.2.2)
#> prettyunits 1.1.1 2020-01-24 [1] CRAN (R 4.2.2)
#> processx 3.8.0 2022-10-26 [1] CRAN (R 4.2.2)
#> progress 1.2.2 2019-05-16 [1] CRAN (R 4.2.2)
#> ps 1.7.2 2022-10-26 [1] CRAN (R 4.2.2)
#> purrr * 1.0.1 2023-01-10 [1] CRAN (R 4.2.2)
#> R6 2.5.1 2021-08-19 [1] CRAN (R 4.2.2)
#> rappdirs 0.3.3 2021-01-31 [1] CRAN (R 4.2.2)
#> RColorBrewer 1.1-3 2022-04-03 [1] CRAN (R 4.2.2)
#> readr * 2.1.4 2023-02-10 [1] CRAN (R 4.2.2)
#> readxl 1.4.2 2023-02-09 [1] CRAN (R 4.2.2)
#> rematch 1.0.1 2016-04-21 [1] CRAN (R 4.2.2)
#> rematch2 2.1.2 2020-05-01 [1] CRAN (R 4.2.2)
#> reprex 2.0.2 2022-08-17 [1] CRAN (R 4.2.2)
#> rlang 1.0.6 2022-09-24 [1] CRAN (R 4.2.2)
#> rmarkdown 2.20 2023-01-19 [1] CRAN (R 4.2.2)
#> rstudioapi 0.14 2022-08-22 [1] CRAN (R 4.2.2)
#> rvest 1.0.3 2022-08-19 [1] CRAN (R 4.2.2)
#> sass 0.4.5 2023-01-24 [1] CRAN (R 4.2.2)
#> scales 1.2.1 2022-08-20 [1] CRAN (R 4.2.2)
#> selectr 0.4-2 2019-11-20 [1] CRAN (R 4.2.2)
#> stringi 1.7.12 2023-01-11 [1] CRAN (R 4.2.2)
#> stringr * 1.5.0 2022-12-02 [1] CRAN (R 4.2.2)
#> sys 3.4.1 2022-10-18 [1] CRAN (R 4.2.2)
#> tibble * 3.1.8 2022-07-22 [1] CRAN (R 4.2.2)
#> tidyr * 1.3.0 2023-01-24 [1] CRAN (R 4.2.2)
#> tidyselect 1.2.0 2022-10-10 [1] CRAN (R 4.2.2)
#> tidyverse * 1.3.2 2022-07-18 [1] CRAN (R 4.2.2)
#> timechange 0.2.0 2023-01-11 [1] CRAN (R 4.2.2)
#> tinytex 0.44 2023-02-01 [1] CRAN (R 4.2.2)
#> tzdb 0.3.0 2022-03-28 [1] CRAN (R 4.2.2)
#> utf8 1.2.3 2023-01-31 [1] CRAN (R 4.2.2)
#> uuid 1.1-0 2022-04-19 [1] CRAN (R 4.2.2)
#> vctrs 0.5.2 2023-01-23 [1] CRAN (R 4.2.2)
#> viridisLite 0.4.1 2022-08-22 [1] CRAN (R 4.2.2)
#> vroom 1.6.1 2023-01-22 [1] CRAN (R 4.2.2)
#> withr 2.5.0 2022-03-03 [1] CRAN (R 4.2.2)
#> xfun 0.37 2023-01-31 [1] CRAN (R 4.2.2)
#> xml2 1.3.3 2021-11-30 [1] CRAN (R 4.2.2)
#> yaml 2.3.7 2023-01-23 [1] CRAN (R 4.2.2)
#>
#> [1] /home/runner/.cache/R/renv/library/r4ds_ita_1st_ed-2aac1073/R-4.2/x86_64-pc-linux-gnu
#> [2] /opt/R/4.2.2/lib/R/library
#>
#> ──────────────────────────────────────────────────────────────────────────────